snakegame 강화학습 도전기
스네이크 게임은 정해진 그리드 격자 배열 안에서 뱀을 움직이면서 1개 이상의 아이템을 먹으면서 몸을 키우는 게임이다. 아이템을 먹으면 몸이 1칸 늘어나게 된다. 자기 몸에 박거나 벽에 박게 되면 게임이 종료된다.
구글에서 snake game이라고 검색하면 플레이해볼 수 있다.
이전에 이 문제를 해결하기 위한 여러 시도가 있었다.
- 격자의 크기를 15로 한 후 DQN으로 문제를 풀려고 시도했지만 실패하였다. 보드의 크기가 크기 때문에 보상을 얻기까지 너무 힘들어 보상의 너무 희소했기 때문인 것 같다.
- 그래서 격자의 크기를 5로 한 후 문제를 풀어서 성공했었다.
하지만 이제 크기 15에 대해 도전해보려고 한다.
0. 초기 설정
- 보상 디자인
- 아이템을 먹을 때마다 보상을 준다.
- 죽을 때마다 음의 보상을 준다.
- observation : (15, 15) 크기의 격자
- 알고리즘 : PPO
1. 희소한 보상 문제
병렬 환경을 4~6개로 늘렸기 때문에 동시에 많은 환경을 탐색하기에 보상을 금방 학습할 것이라 예상했으나 실패하였다.
- 양의 보상은 들어오지 않고 죽거나 음의 보상만 주어지니 0의 보상을 받는 행동을 하기 위해 같은 자리를 계속 멤돈다.
- 이러한 행위를 방지하기 위해 그냥 움직이는 행동에 대해 약한 음의 보상을 주었다. 그랬더니 음의 보상의 누적보다 죽는게 낫겠다 싶어서 죽어버린다.
- 이럴 경우 에피소드가 아예 끝나지 않는 현상이 발생하여 TimeLimit 을 10000으로 조정하였다. 격자의 개수인 225개에 대한 짐작된 숫자이다.
- 그냥 죽을 경우 보상을 -10, 의미 없는 움직임일 경우 -0.001 이래도 TimeLimit을 꽉 채워서 죽는 발생하였다. Truncation으로 에피소드가 끝날 경우 다음 보상이 계산된다는 것과 discount factor에 의해 TD Target이 더 작기 때문일 것이다.
2. 렌더림 메모리 문제
학습중에 메모리가 치솟으며 중간에 학습이 꺼지는 현상이 발생하였다.
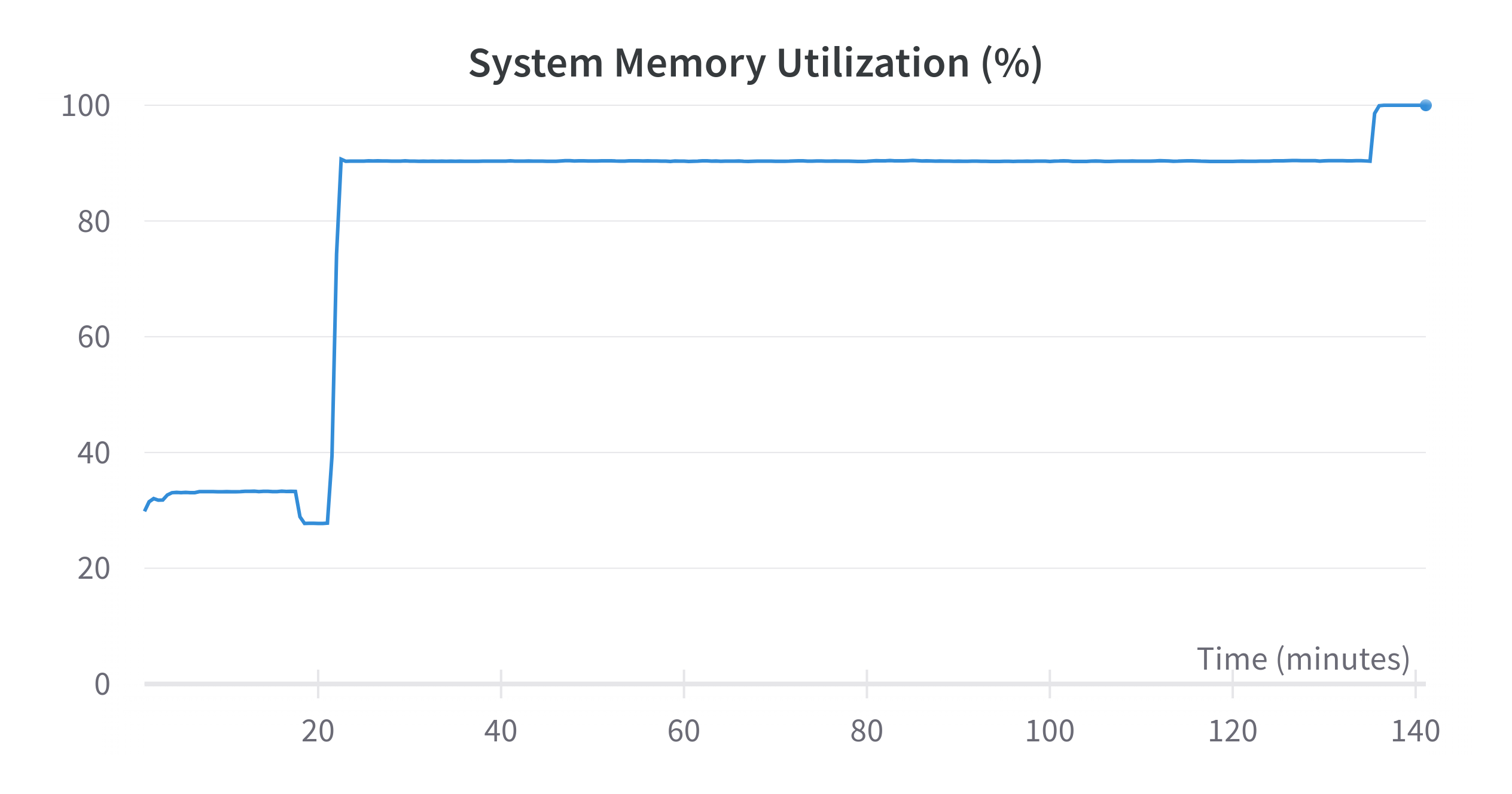
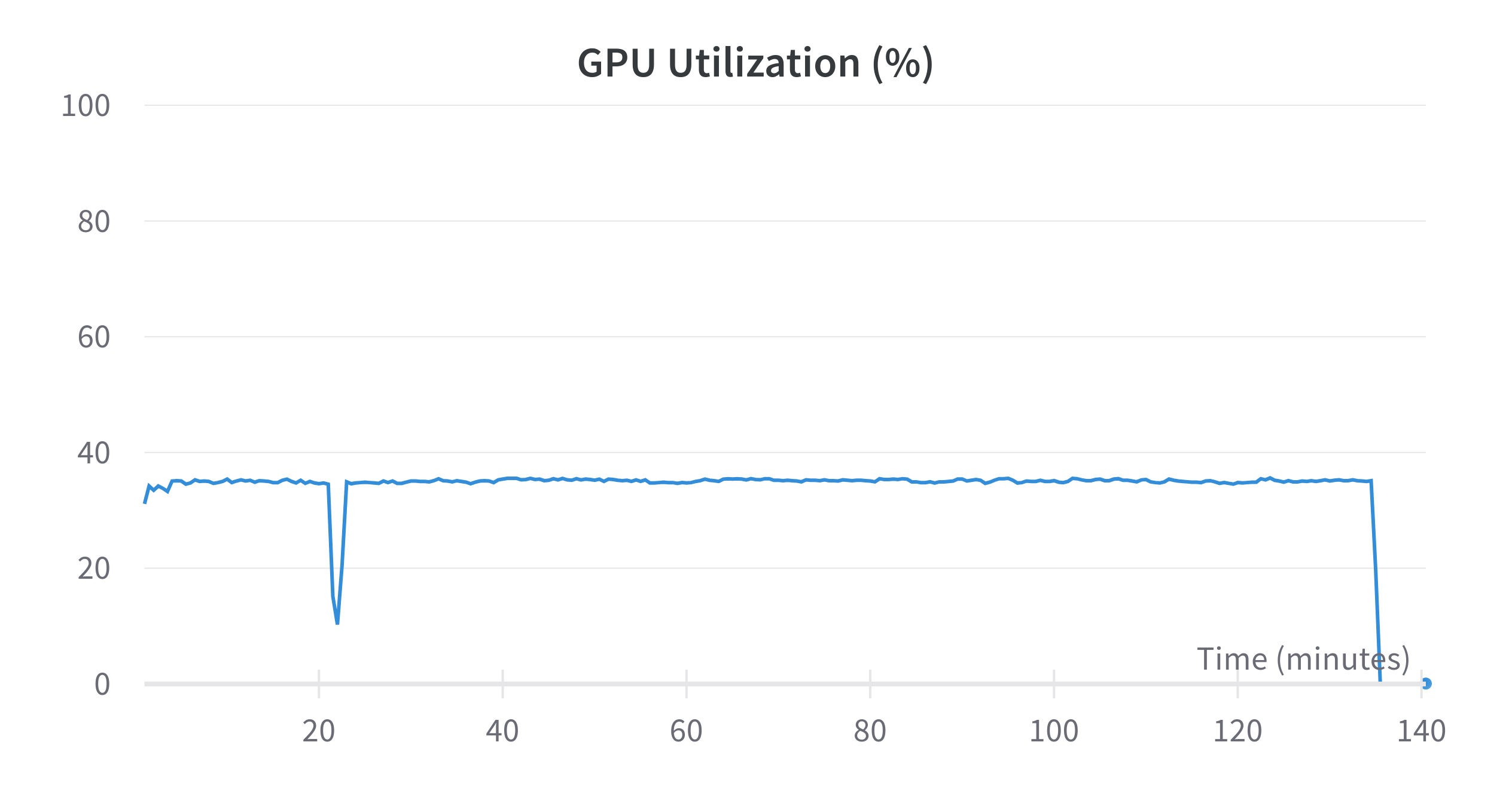
메모리 사용량이 치솟더니 함께 학습이 종료되었다.
오픈소스 CleanRL을 사용했기 때문에 코드 자체에는 문제가 없다고 생각하고 일단 환경에 문제가 있지 않을 까 생각했다.
가장 유력한 후보인 렌더링 문제가 아닐까 생각하였고 200 에피소드마다 에피소드를 동영상으로 렌더링하는데 이 문제가 아닐까 싶었다. 게다가 이 영상을 wandb로 전송하니 말이다.
렌더링을 켰을 경우 모두 같은 문제가 생겼는데 일단 렌더링 옵션을 꺼놓고 (영상 출력이 안되게 해놓고) 학습을 해보았는데 나머지를 동일하게 한 결과 문제가 발생하지 않아 문제가 렌더링 문제가 아닐까 가정하였다.
그리고 고의로 절대 에피소드가 끝나지 않도록 에이전트를 설계하고 실험하였다.
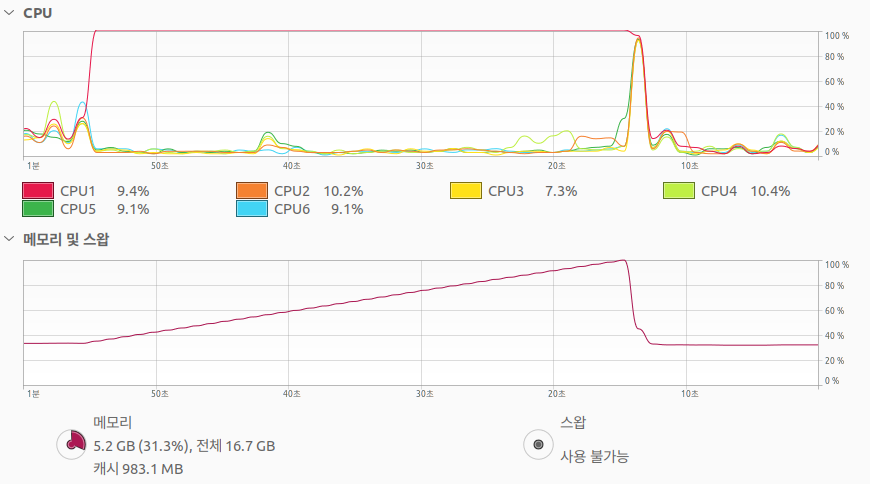
결과는 예상대로였다. 메모리가 치솟고 프로그램이 종료된다.
실험 결과를 통해 파라미터나 보상 전략을 수정하려고 하였으나 여러 문제가 있었다. 이에 대해 몇가지 대처사항이 있다.
- FPS를 높여서 영상의 크기를 줄인다.
- 렌더링을 하지 않는다.
- 무한루프를 벗어나도록 에이전트를 디자인한다.
근데 지금은 일단 실험의 안전성을 위해 당분간 렌더링을 하지 않고 실험 결과는 에피소드의 길이로 추론해보기로 했다.
3. 작은 환경에서 테스트
분위기를 환기하기 위해 일단 간단한 코드를 돌려보았다.
이전에는 5 X 5 를 DQN으로 돌렸는데 이번에는 많은 병렬처리가 가능해져 8 X 8로 돌려보았다. 숫자에 큰 의미는 없다.
쉽게 해결이 가능했다.
4. 에서 언급할 내용에 대한 생각으로 보통의 행동(보상도 안먹고 죽지도 않는 행동)에 대해 -0.01을 보상으로 주었다. 하지만 격자가 작아져서 해결된 것인지, 보상 때문인지는 확실하지 않다.
아래 링크에서 플레이 영상을 확인할 수 있다.
Reinforcement Learning SnakeGame 8 X 8 - Youtube
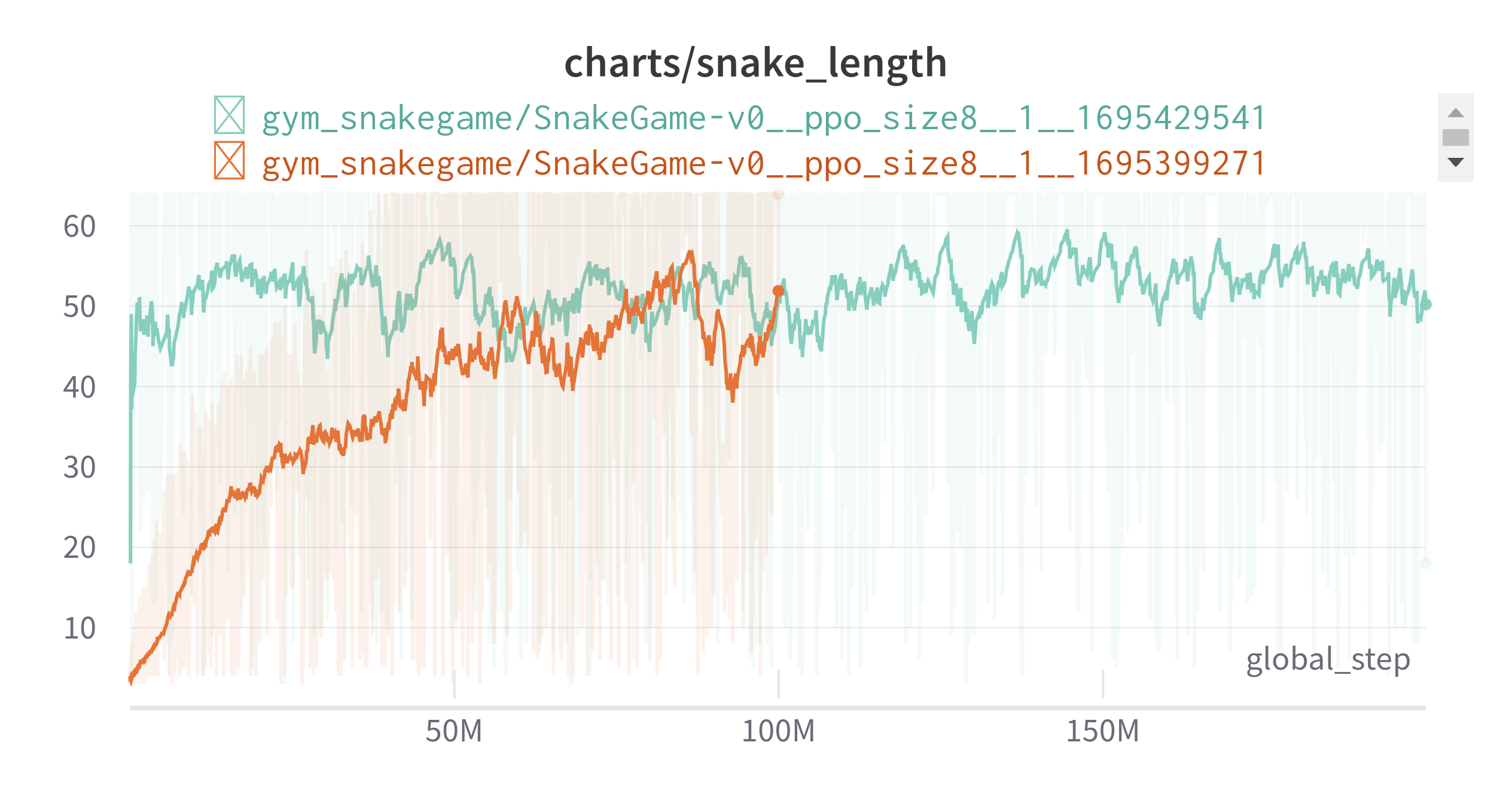
- 주황색으로 학습한 후 weight를 저장한 후에 연두색에서 학습을 계속하였다.
4 무한루프 vs 포기
포기 : 시작하자마자 게임을 안좋은 쪽으로 끝내는 행위 (Ja살을 직접 쓸 수 없어서 쓴 말)
결국 에이전트는 보상을 최대화하는 방향으로 행동을 선택하는데
벽에 박아서 죽는 것이 너무 큰 음의 보상을 준다면 그것을 피하기 위해 양의 보상을 찾으러 갈 수도 있지만 양의 보상을 찾지 못할 경우 작은 음의 보상을 주는 무한루프 행동에 빠질 수 있다.
그렇다고 무한루프를 방지하기 위해 보통의 행동에 대해 음의 보상을 더 높인다면 벽에 바로 박아버리는 현상이 발생한다.
그럼 둘 중에 하나를 선택해야 한다. 환경은 snakegame이라 가정하겠다.
이전에는 똑같이 별로인 것 아닌가 생각했는데 곰곰히 생각해봤는데 다른 점이 있다. 갱생의 여지는 ‘포기’ 쪽이 더 있다. 왜냐하면 무한루프의 경우 10000 스텝(TimeLimit)을 무의미한 행동에 쓰게 되는데 ‘포기’의 경우 최대한 빨리 끝낸다면 10스텝 정도다. 그러면 1000번의 에피소드를 더 할 수 있는데 최대한 빨리 끝내는 과정에서 그 중간에 아이템을 먹을 확률이 더 높다.
무한루프의 경우는 말 그대로 무한루프이기 때문에 해당 경로에 아이템이 없다면 (또는 그게 좋은 것인지 학습하기 전이라면) 10000스텝을 생으로 날리게 된다.
그래서 보상을
$\text{(TimeLimit)} \times \text{(Normal Action)} < \text{(가장 빠른 포기 행위)}$
로 지정해서 exploration의 여지를 최대한 늘려보기로 했다.
5. MDP 만족 여부
작은 환경에서 성공을 하였지만 의문이 있었다. 왜 snake_length가 64에 도달하지 못할까?
신경망이 작기 때문일까? 하고 여러 고민을 해보던 중 치명적인 실수를 발견하였다.
내가 신경망에 주입하는 observation은 MDP를 만족하지 못한다.
예를 들어 환경에서 observation은 다음과 같다.
- 0 : snake
- 1 : blank
- 3 : head
- 5 : target
위 처럼 구현하였을 때 특정 상황에서 에이전트입장에서 어떻게 보이는지 보자.
snake, blank, head, target을 각각 흰색, 검은색, 빨간색, 초록색이라 해보자
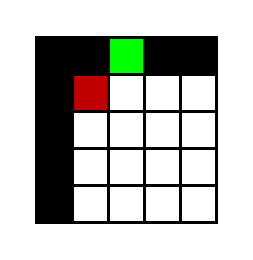
이라면 뱀은 어디를 향해 가는 것일까?
몸통의 위치에 의하면 위(↑) 아니면 왼쪽(←)으로 향하고 있을 것이다. 즉 이 observation만 보고는 환경을 정확히 파악할 수 없다.
예를 들어서 위로 가고 있는 상황에서 오른쪽을 선택하게 된다면 몸통에 부딪혀 바로 게임이 끝나게 되지만, 왼쪽으로 가고 있을 경우 오른쪽을 선택하면 아무 일도 일어나지 않기 때문에 왼쪽으로 한 칸 전진하게 될 것이다. (진행방향과 반대방향키는 눌러도 아무 변화가 없다.)
그럼 이런 상황에서는 무조건 위로 가게 하면 되지 않나? 할 수 있지만 타겟이 바로 왼쪽에 있고 왼쪽으로 바로 가는 것이 최적의 행동이라면 그것을 선택 할 수 없게 된다.
하나가 더 있다. 한칸 앞으로 간다면 꼬리가 한칸 비게 될텐데 어느 공간이 비게 될까? 이것은 더 복잡하다. 뱀이 어떻게 꼬여서 저런 직사각형 모양을 형성했을 지 모르기 때문에 파악하기가 더 힘들다.
일단 해당 문제에 대해 info에 snake의 방향도 같이 넣어주기로 하였고 학습을 위해서는 POMDP를 최대한 MDP로 취급할 수 있게 LSTM을 활용하던가 FrameStack을 활용할 생각이다.
6. PPO-LSTM 1
PPO-LSTM을 시도했다. 하지만 학습이 너무나 느려서 FrameStack을 시도했다. 하지만 이는 완벽한 대안이 아닌데 그 이유는 아래 서술한다.
7. FrameStack-1
MDP를 만족할 수 있게 FrameStack을 이용했다. 그렇다고 엄밀하게 충족되는 것은 아니다. 다음 그림를 보자
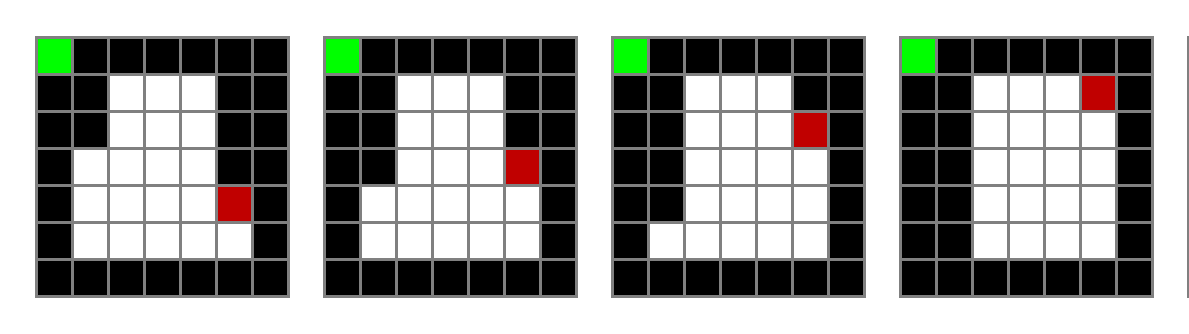
마지막 프레임에서 뱀의 머리는 윗 방향을 향하고 있다는 것을 알게 되었으므로 왼쪽 방향을 선택하지 않을 것이다.
위로 올라가는 행동을 다시 선택하여 계속 위로 올라간다고 해보자 그럼 다음 observation은 다음과 같을 것이다.
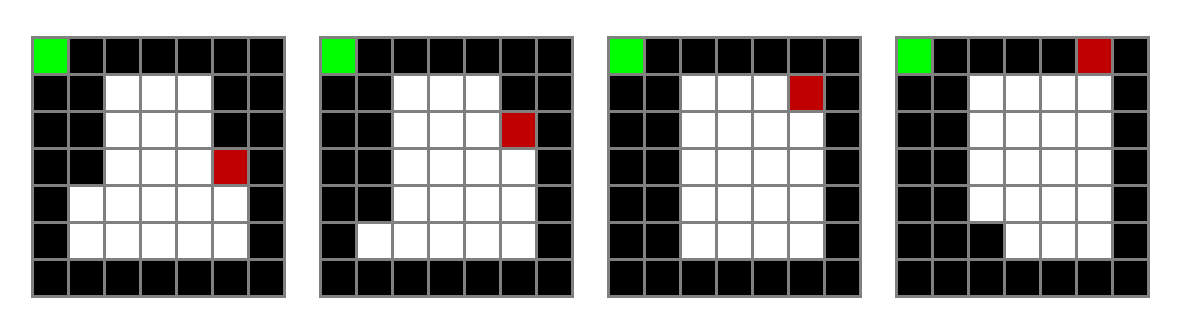
그럼 여기서 문제가 발생한다. 여기서 왼쪽으로 꺾는다면 다음으로 없어지는 공간은 어디일까?
대표적으로 다음과 같은 두 가지 경우가 있다. (더 있지만 편의를 위해 두가지만 생각해보자)
첫번째라면 꼬리에서 오른쪽 블록이 비게 될 것 이고 두번째라면 꼬리에서 위쪽 블록이 비게 될 것이다.
이는 FrameStack으로도 알수 없는 부분이다. 그래도 어느정도 완화되는 부분이 있기에 학습을 진행해보았다.
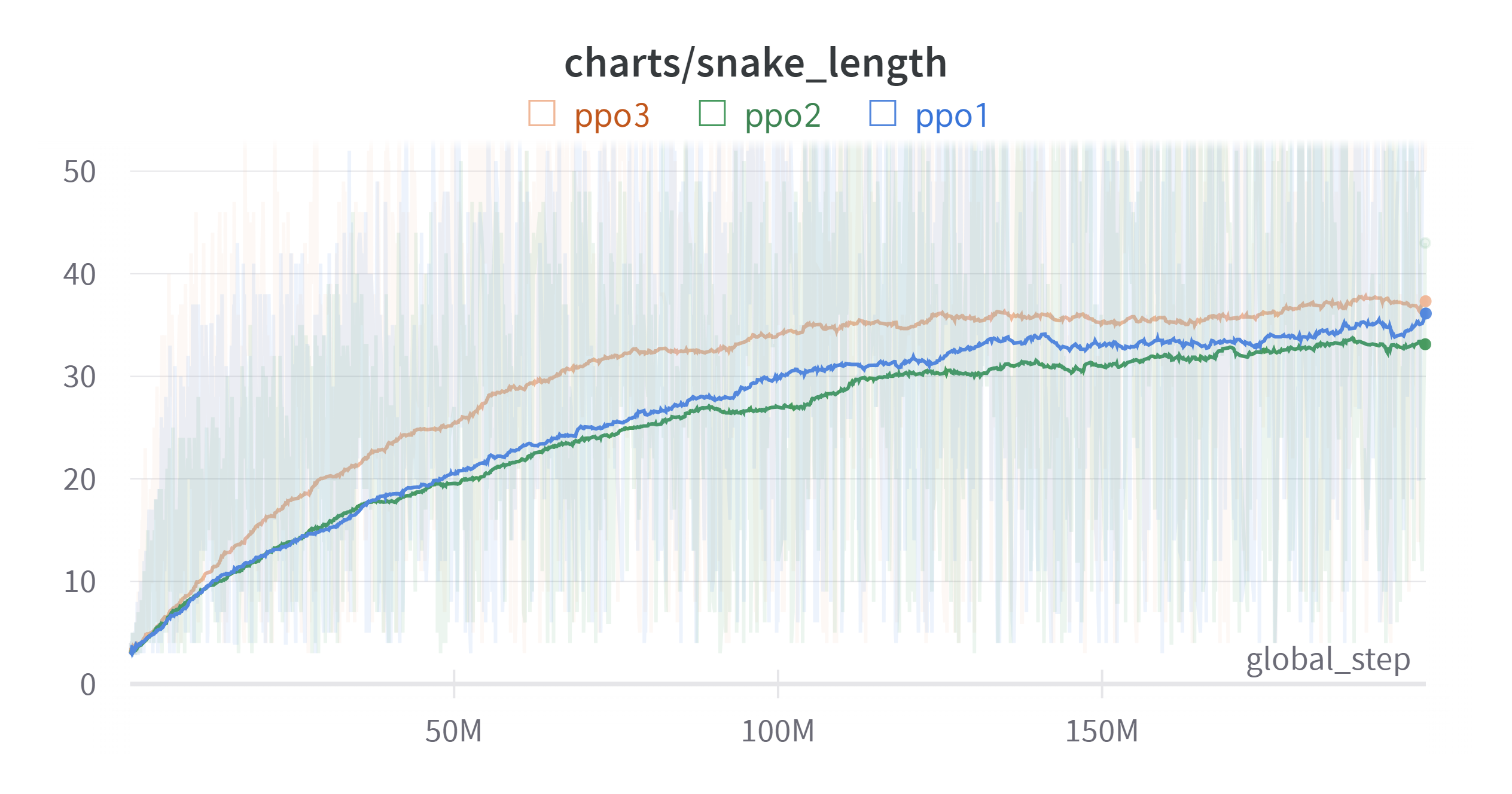
- ppo1 : FC Layer : 512
- ppo2 : FC Layer : 2024
- ppo3 : FC Layer : 512, FrameStack : 4
Time Weighted EMA: 0.99
Time Weighted EMA: 0.99
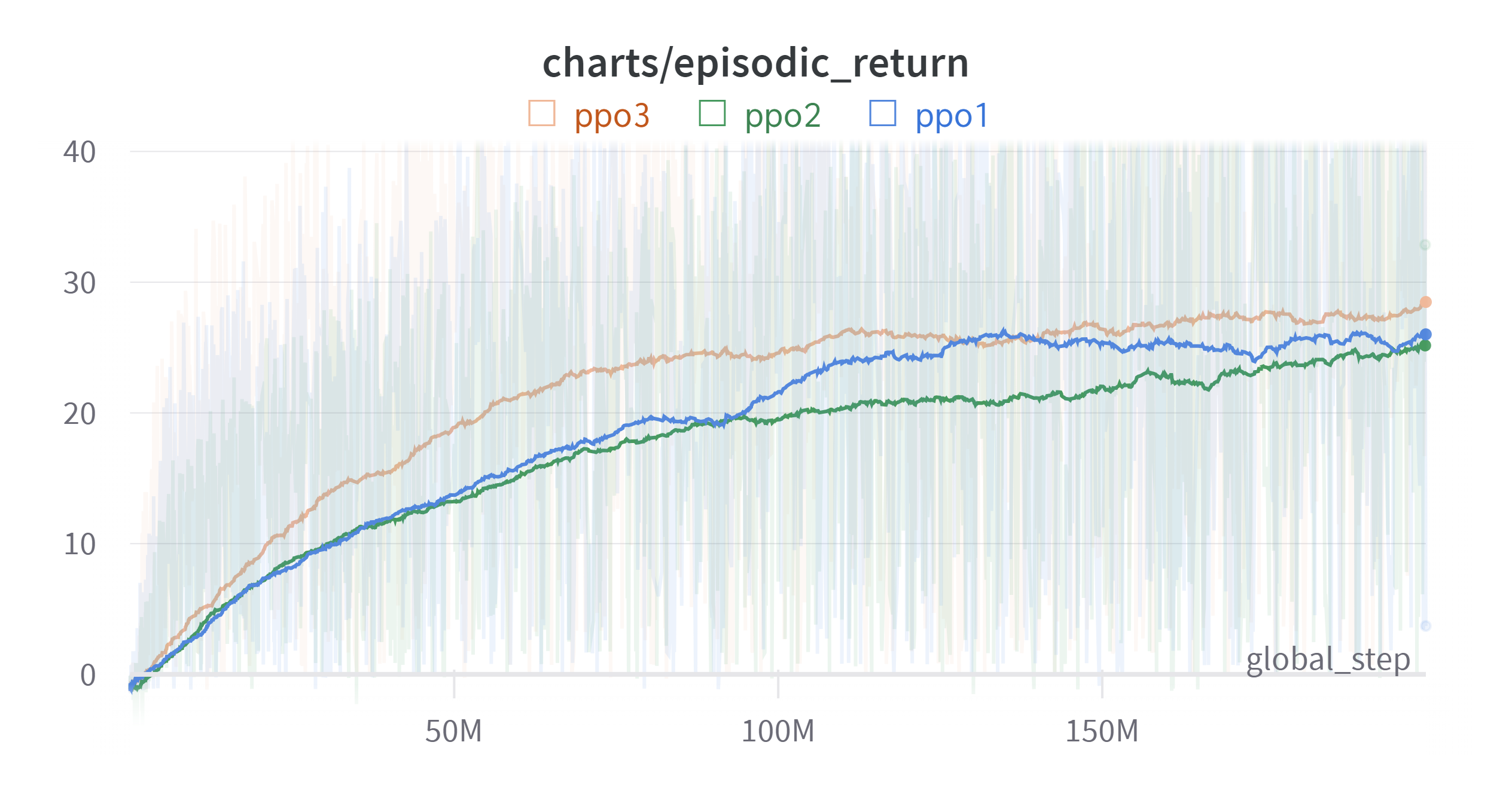
그래프를 보면 100M 까지는 학습이 상당히 빨리 진행되는 것을 볼 수 있다. 하지만 그 이후부터는 학습이 느려지는 것을 볼 수 있다. snake의 길이가 길어지면서 몸통의 구조를 파악하기 훨씬 더 어려워지기 때문인 것 같다.
실험은 하나라서 정확한 파악은 힘들지만 snake_length은 비슷해질 수도 있겠지만 episodic_return의 경우는 유의미한 차이를 보이기 때문에 일단 FrameStack이 어느 정도 효과는 있었다고 볼 수 있겠다.
하지만 여전히 한계는 있어보여 다른 방법을 더 찾아보기로 했다. LSTM의 경우는 학습을 오래 하면 되는 것 같긴 하지만 (컴퓨터를 써야하는) 현실적인 한계가 있어 어떻게 학습을 이어갈지에 대해 고민을 해봐야겠다.
8. FrameStack-2
FrameStack의 개수가 학습이 느려지는 것을 완화해줄 수 있지 않을까 싶어서 FrameStack의 개수를 4에서 16으로 늘려보았다.
실험 결과는 다음과 같다.
| ppo1 | ppo2 | ppo3 | ppo4 | |
|---|---|---|---|---|
| FrameStack | 1 | 1 | 4 | 16 |
| FC Layer | 512 | 2024 | 512 | 512 |
| Channel | 1-16-32-64 | 1-16-32-64 | 4-32-64-64 | 16-32-64-64 |
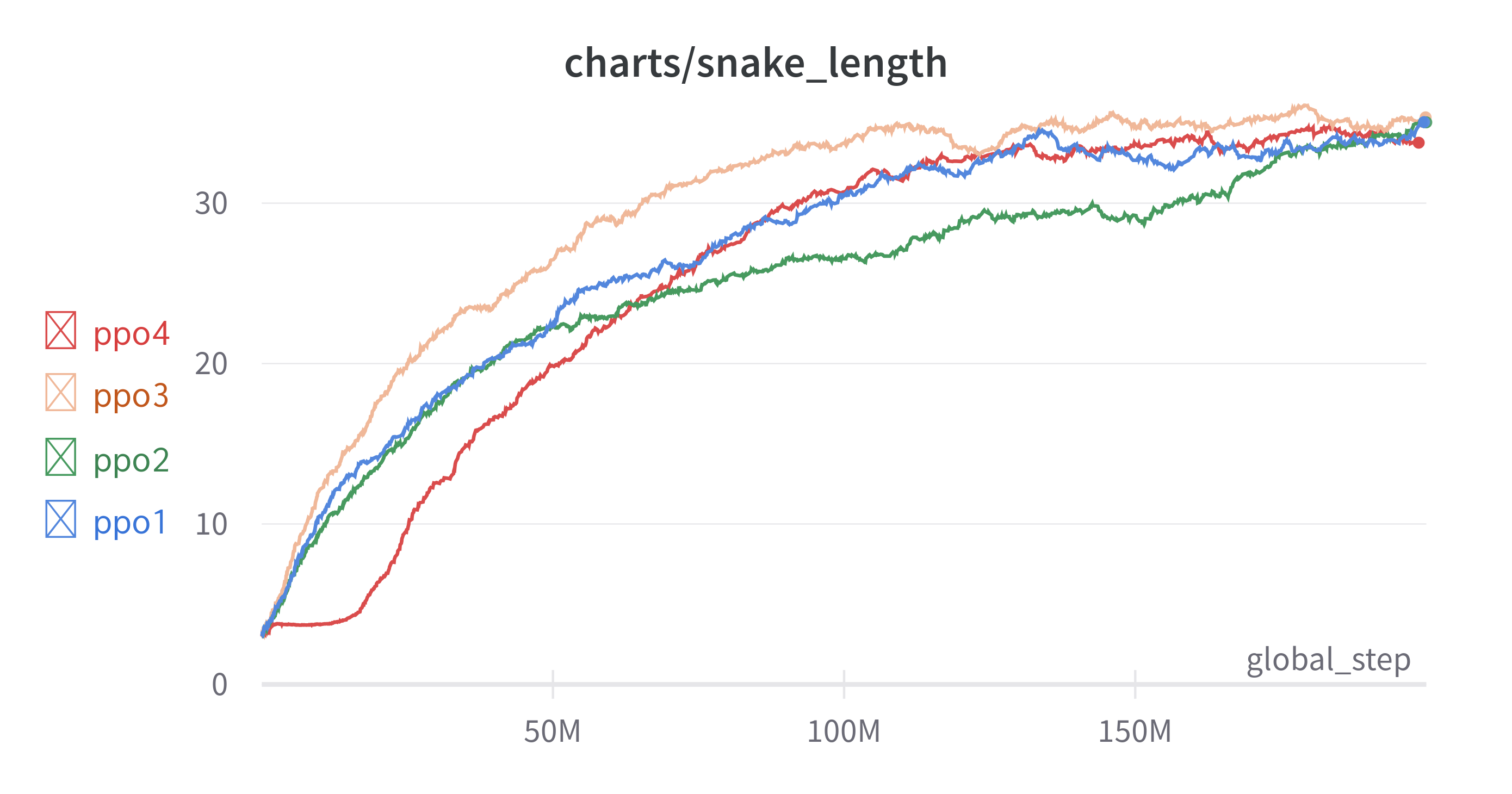
초반에 약 20M까지는 학습이 느리게 진행되고 이후에는 급속도로 학습이 되는 것을 확인할 수 있다. 이로 인해 다른 실험에 비해 높은 성능을 기대했지만 뱀의 길이 35 부근에서 학습이 정체되었다. 그도 그럴것이 뱀의 끝부분을 알고 싶다면 뱀의 길이만큼 FrameStack을 해야 하는데 15 X 15의 경우 215개의 FrameStack을 할 경우 학습이 너무 오래걸린다. 그래서 적당하게 16개로 설정하여 FrameStack의 개수를 늘려보았지만 한계가 있었다. 뱀의 길이가 16을 넘어가면 역시 위에서 언급했던 MDP문제가 해결이 되지 않는 것은 같기 때문이다.
학습을 더 하면 어떻게든 성능은 오를 수 있겠지만 MDP가 아닌 것은 자명하기 때문에 이 문제를 해결하면서 성능도 올릴 방법을 찾아야겠다.
9. Local Optimum
뱀의 길이만큼 FrameStack을 하면 성능이 좋아질까? 작은 환경에서 테스트 에서는 최고 64에서 평균 60을 넘지 못했는데 넘을 수 있을까?? 한번 실험해보았다.
Time Weighted EMA: 0.99
board_size는 8이다. 주황색이 FrameStack하지 않은 것이고 초록색이 FrameStack 64를 한 것이다. 두배로 많은 global_step에도 불구하고 성능은 더 높아지지 않았다.
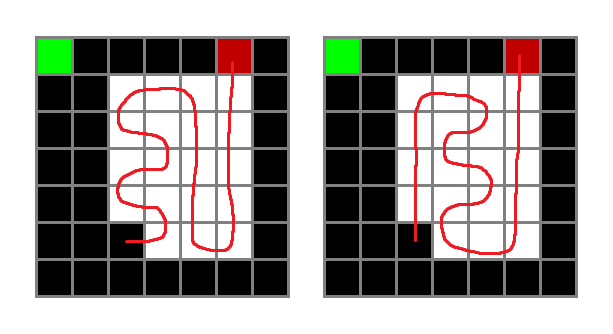
실험이 한 번이기에 단정할 수는 없지만 이번 실험에서 특이한 점이 있었다. 초록색 그래프를 보면 희미하게 보이지만 snake의 길이가 60을 넘지 못한다. 최댓값은 64인데도 말이다.
영상을 보니 다음과 같은 현상이 나타났다.
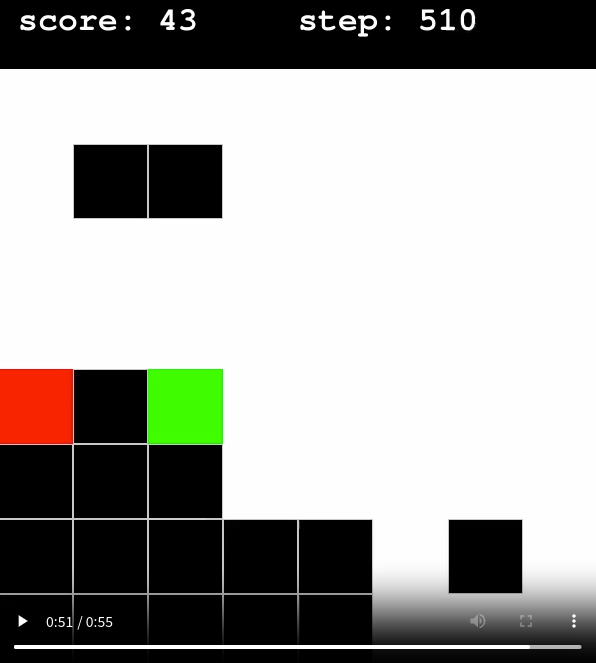
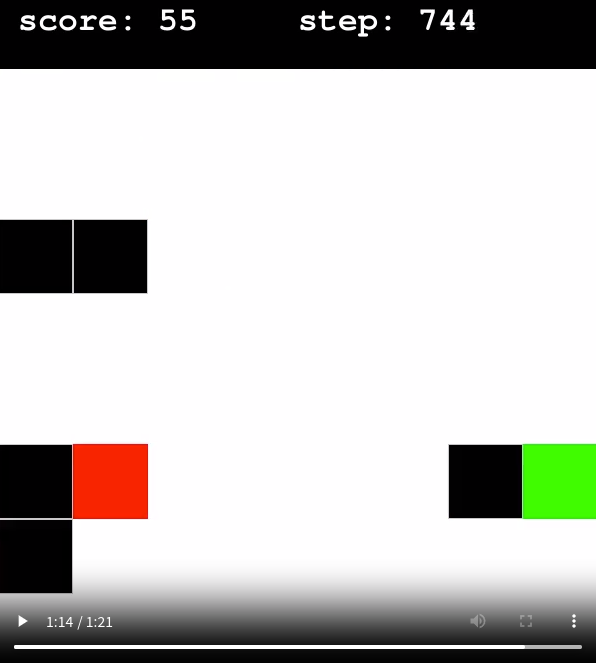

셋은 각각 다른 사진이다. 그런데 특이하게 저렇게 자꾸 두칸씩 비슷한 공간을 비운다. 이유는 모른다. FrameStack과 관계된 일인지, 아니면 그저 Local Optimum인지는 모르겠다. 근데 어쨌든 1 Frame 환경을 이기지도 못했고 Local Optimum에 빠졌다.
그래서 board_size=15 에서도 과연 FrameStack을 늘리는 것이 근본적인 해결책이 될 수 있을지 의문이 생겼다.
10. MDP 만족
MDP를 만족하는 환경을 만드는 법을 생각해내었다. 간단히 설명하면 board의 size를 n이라 했을 때 $n \times n + 1$ 를 item으로 하고 1부터 꼬리까지 1씩 높인다.
예를 들면 다음과 같다.
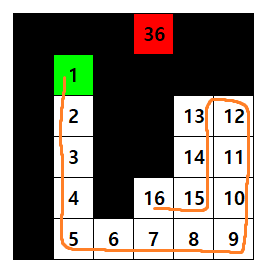
실제 학습시에는 Item의 숫자로 나눠서 정규화하여 사용한다.
11. 학습
그럼 이것을 가지고 오랫동안 학습을 진행해보았다. 학습 그래프는 다음과 같다.
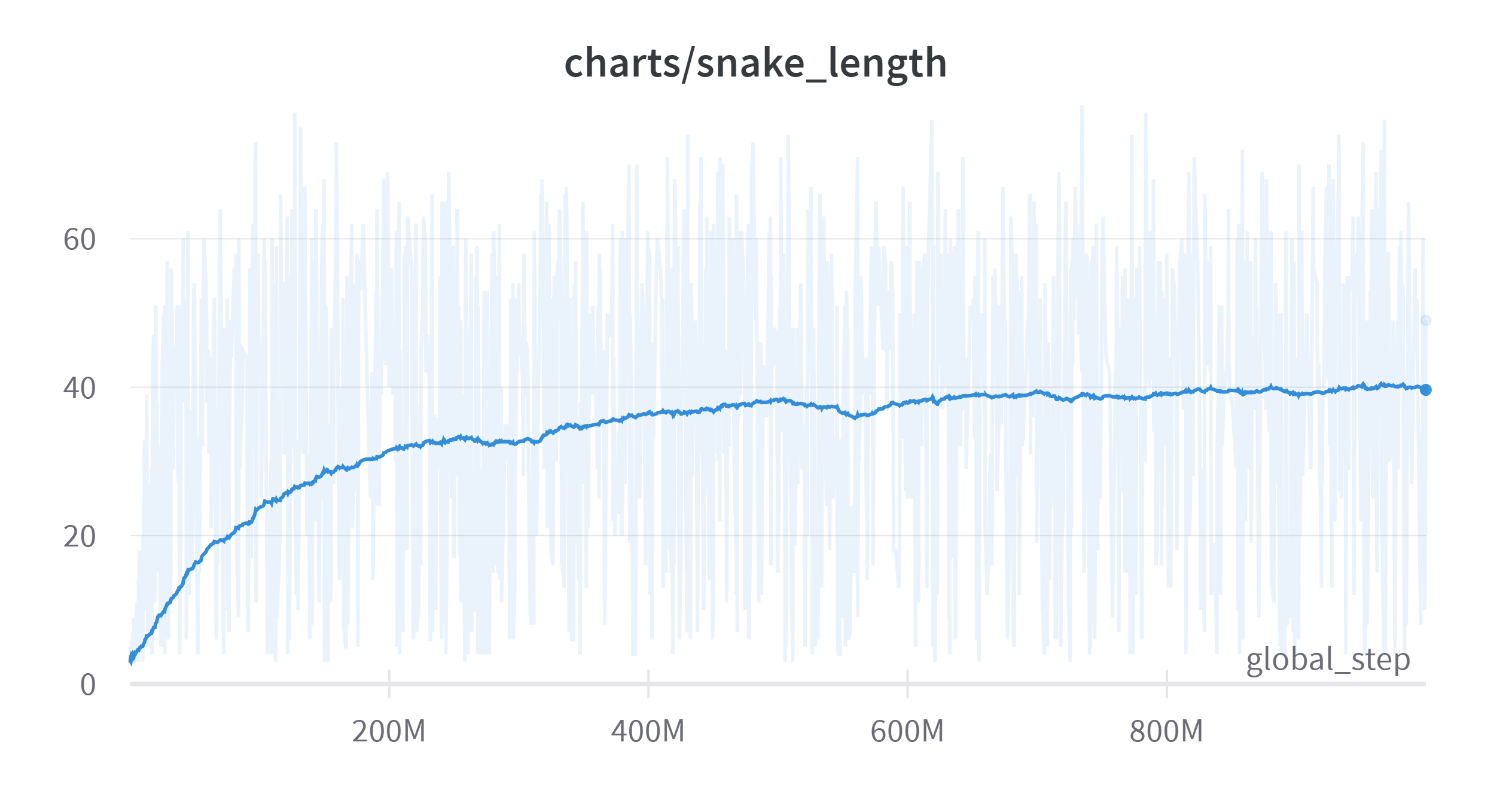
Time Weighted EMA: 0.99
보드의 크기가 15이고 칸의 크기가 215개일 때 이다.
200M까지는 학습이 빠르게 진행되었다. 그리고 200M 이후부터는 학습이 느려지는 것을 볼 수 있다. 그리고 500M 이후부터는 학습이 거의 진행되지 않는 것을 볼 수 있다.
이제는 환경에 대한 개념보다는 학습의 알고리즘, 혹은 컴퓨터의 성능에 대한 한계로 보인다. 성능이 좋다고 하여도 결국 어느 시점 이상에서 그래프가 다시 위로 올라갈 수 있을지도 의문이다. 보드의 크기인 15도 너무 큰 것이 아닌가 하는 생각도 든다. 관련하여 실험이나 공부를 더 해볼 생각이다.
12. 보상 정책 변경
보상 정책에 대해 변경을 해 보았다. 이대로 간다면 시간에 의해서만 해결되는 상태가 될 확률이 높기 때문에 다른 요소들을 바꿔보려고 했다. 보상에 대해 바꿔보려고 했는데 두 가지를 바꿔봤다.
- 아이템을 먹을 때, 죽을 때 각각
+1/-1의 보상을 얻었는데 이를+5/-5,+10/-10으로 바꾼다. - 빈 공간으로 움직였을 때 -0.01의 보상을 얻었는데 이를 -0.1, -0.5 등으로 바꿔본다.
그리고 실험을 좀 더 빠르게 하기 위해 board_size를 12로 해봤다 실험 결과는 다음과 같다
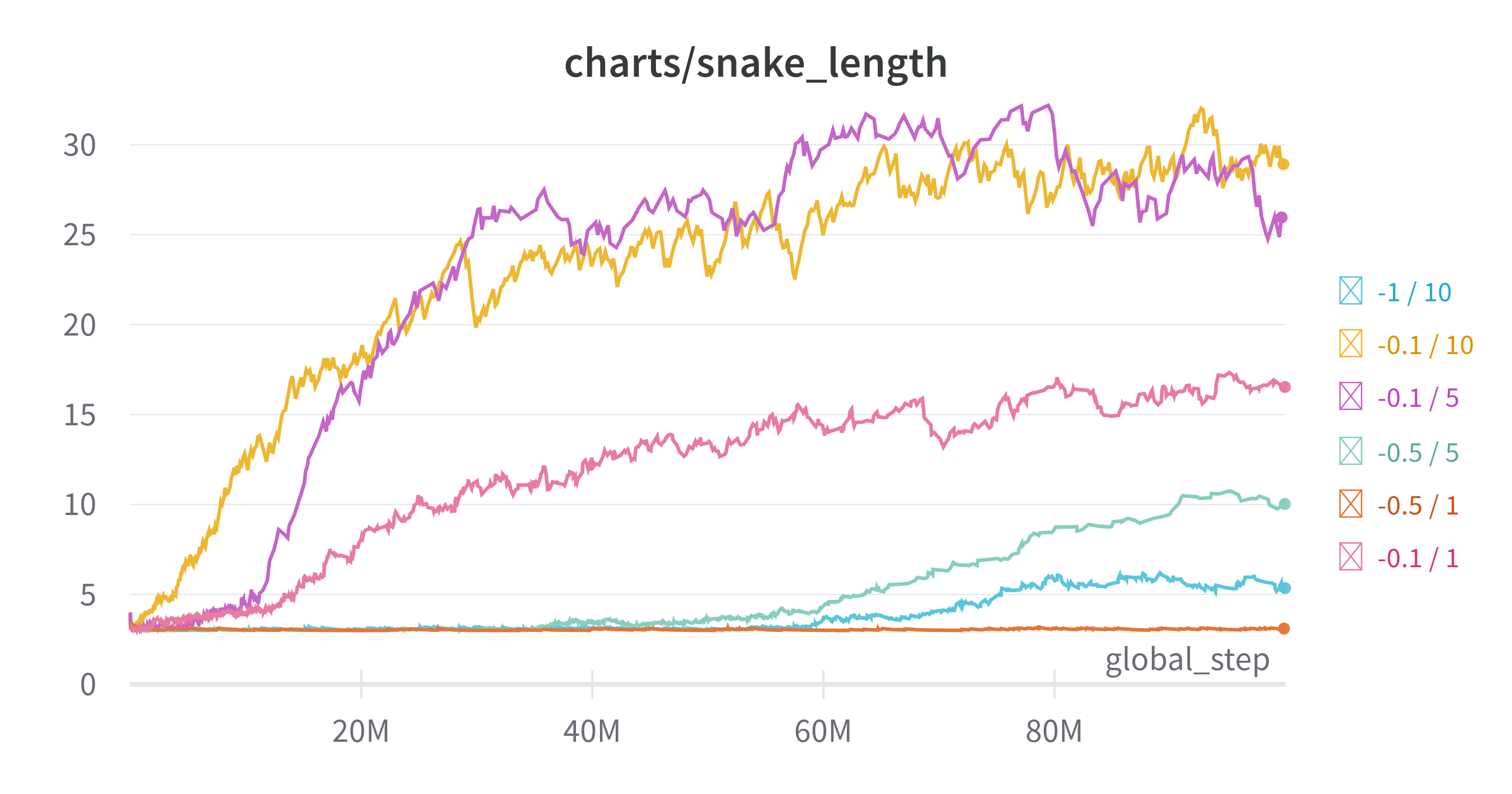
Time Weighted EMA: 0.99
-0.1/10, -0.1/5 가 가장 높은 성능을 보였다. 다른 것들은 빈 공간에 움직이는 경우의 음의 보상과 아이템을 먹을 때의 양의 보상의 절댓값의 차이가 작은데, 성능 높은 두 개는 그 차이가 비교적 큰 편이며 아이템을 먹었을 때 보상이 높은 경향이 있다. 보상에 대해 편차를 크게 하지 않기 위해 1로 하였으나 더 높여도 되지 않을까 하는 생각이 들었다.
13. 음의 보상의 누적
2048 게임 강화학습 도전기 - 13. 용서해줘 다음부터 잘할게 와 같은 현상이 일어났다. (번호도 같다) 차트부터 보자
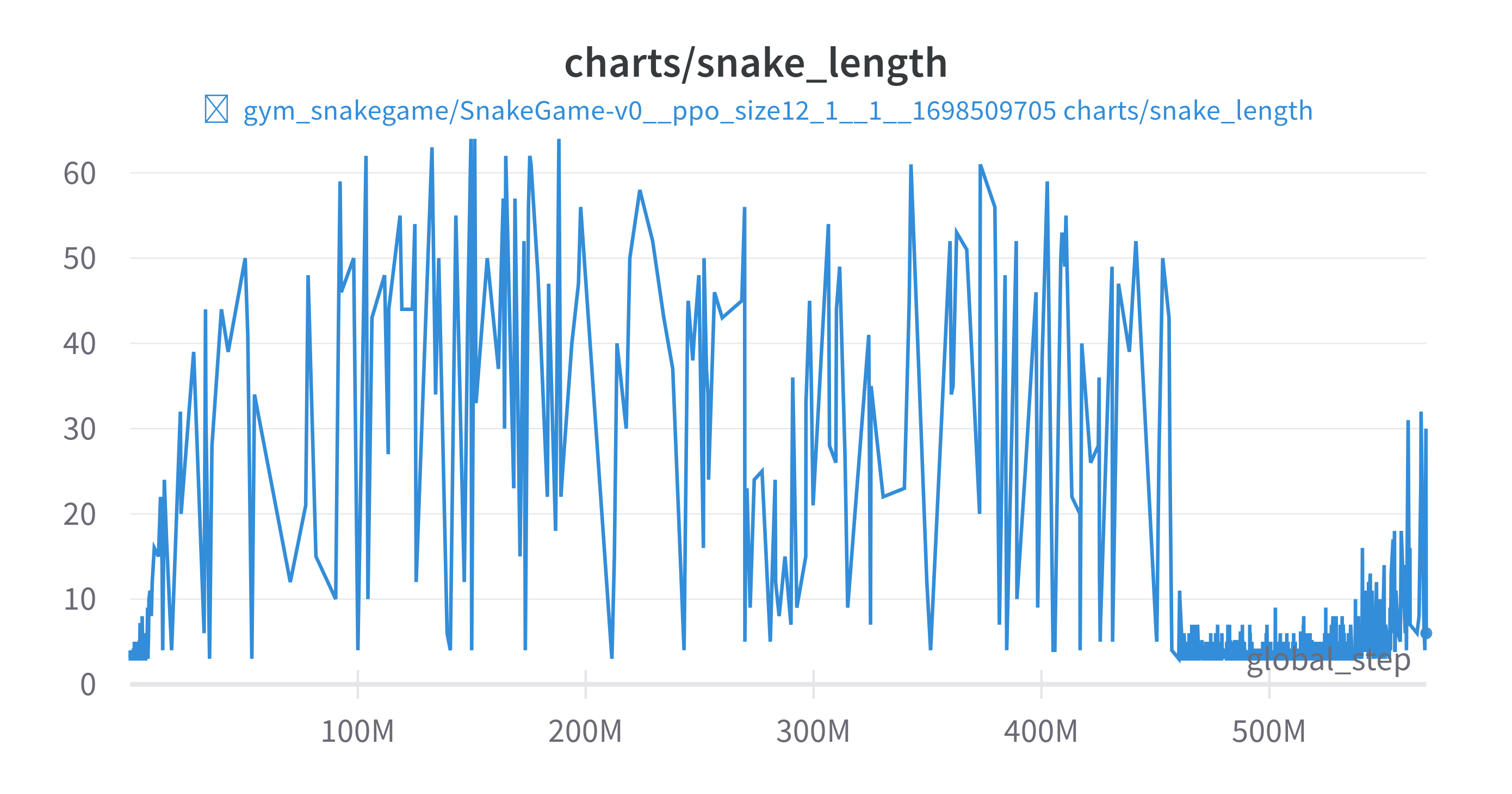
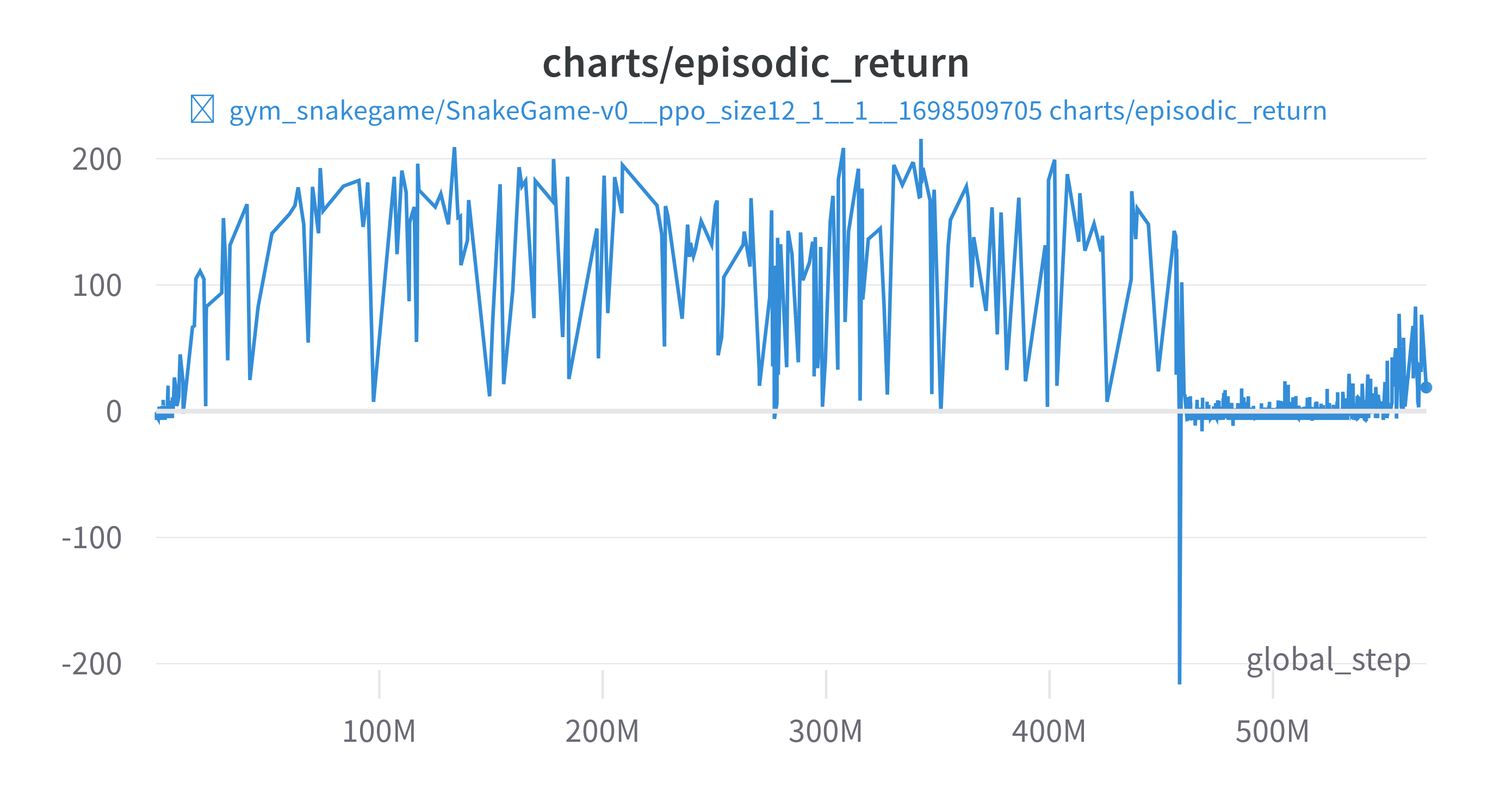
보상은 다음과 같다
- 죽음 : -5
- 아이템먹음 : +5
- 빈 공간 움직임 : -0.1
그림에서 보다시피 450M 부근에서 큰 음의 보상을 받고나서 정책이 완전히 망가졌다. 오랜시간 해당 상태에 대해서 회복을 하지 못하는 모습을 볼 수 있다. episodic_return이 낮은 10개의 에피소드를 보자
| global_step | episodic_length | episodic_return | snake_length |
|---|---|---|---|
| 458188608 | 2574 | -216.40 | 12 |
| 425515328 | 1819 | -146.00 | 11 |
| 460265080 | 783 | -62.80 | 7 |
| 463606896 | 522 | -46.90 | 5 |
| 529279624 | 342 | -39.10 | 3 |
| 559211032 | 659 | -30.00 | 11 |
| 464593056 | 377 | -27.30 | 6 |
| 534497664 | 321 | -26.80 | 5 |
| 478714120 | 294 | -24.10 | 5 |
| 537885824 | 243 | -24.10 | 4 |
많은 음의 보상을 받았던 에피소드에서 에피소드의 길이가 확실히 긴 것을 볼 수 있다. 빈 공간은 한 스텝당 -0.1으로 했으니 사실상 무한루프에 빠졌다고 볼 수 있다.
그럼 어떻게 해야 할까. 에피소드의 길이를 제한시켜야 할까, 에피소드의 길이로 오름차순 정렬하면 다음과 같다.
| global_step | episodic_length | episodic_return | snake_length |
|---|---|---|---|
| 458188608 | 2574 | -216.40 | 12 |
| 425515328 | 1819 | -146.00 | 11 |
| 200630848 | 1348 | 186.70 | 67 |
| 149633496 | 1304 | 175.80 | 64 |
| 146415296 | 1285 | 193.00 | 67 |
| 196509248 | 1259 | 200.70 | 68 |
| 112258488 | 1229 | 198.60 | 67 |
| 192864064 | 1226 | 183.60 | 64 |
| 364342736 | 1216 | 189.70 | 65 |
| 115377112 | 1200 | 191.30 | 65 |
에피소드 길이가 가장긴 2개가 에피소드 리턴이 가장 낮은 두개와 일치한다. 하지만 언제부터 끊어야 할지 애매하다, 사이즈 12의 보드에서 144개의 아이템을 획득하는데 67개를 얻는데 1348 step이라면 144개를 얻는 데는 3000 step은 훌쩍 넘기는 것이 자명하니 2500으로 끊기에도 애매하다.
그래서 일단은 learning_rate랑, clip-coef를 각각 0.0001, 0.1로 줄여서 실험해보기로 했다.
14. 채널의 명시적인 분리
특징적인 요소들을 채널을 분리하여 학습할 경우 성능이 더 좋게 나타났다.
gym-snakegame/README.md 에 서술한 바와 같이
채널의 개수를 1로 설정하면 모든 요소를 한 채널에 나타내고, 2로 설정하면 뱀과 아이템을 분리하고, 4로 설정하면 머리, 몸, 꼬리, 아이템으로 분리한다.
그래서 위 내용에 대해 실험을 해 보았다.
원래 이 내용이 먼저였으나 실험을 모르고 삭제하여, 다시 학습하여 그래프를 그렸기에 15. 단락의 action masking 내용을 포함했다.
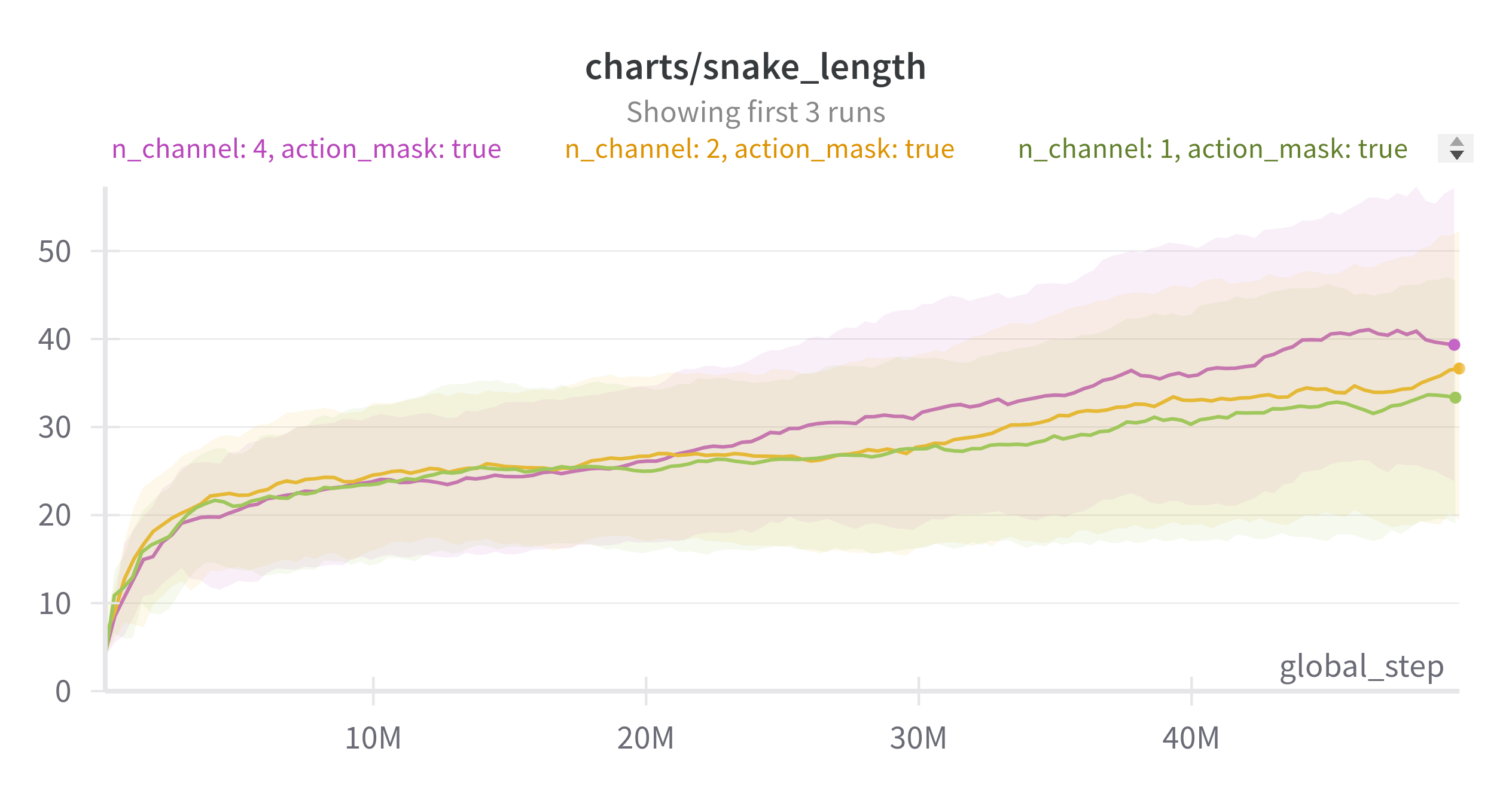
EMA: 0.9, 6 seed, board size : 12
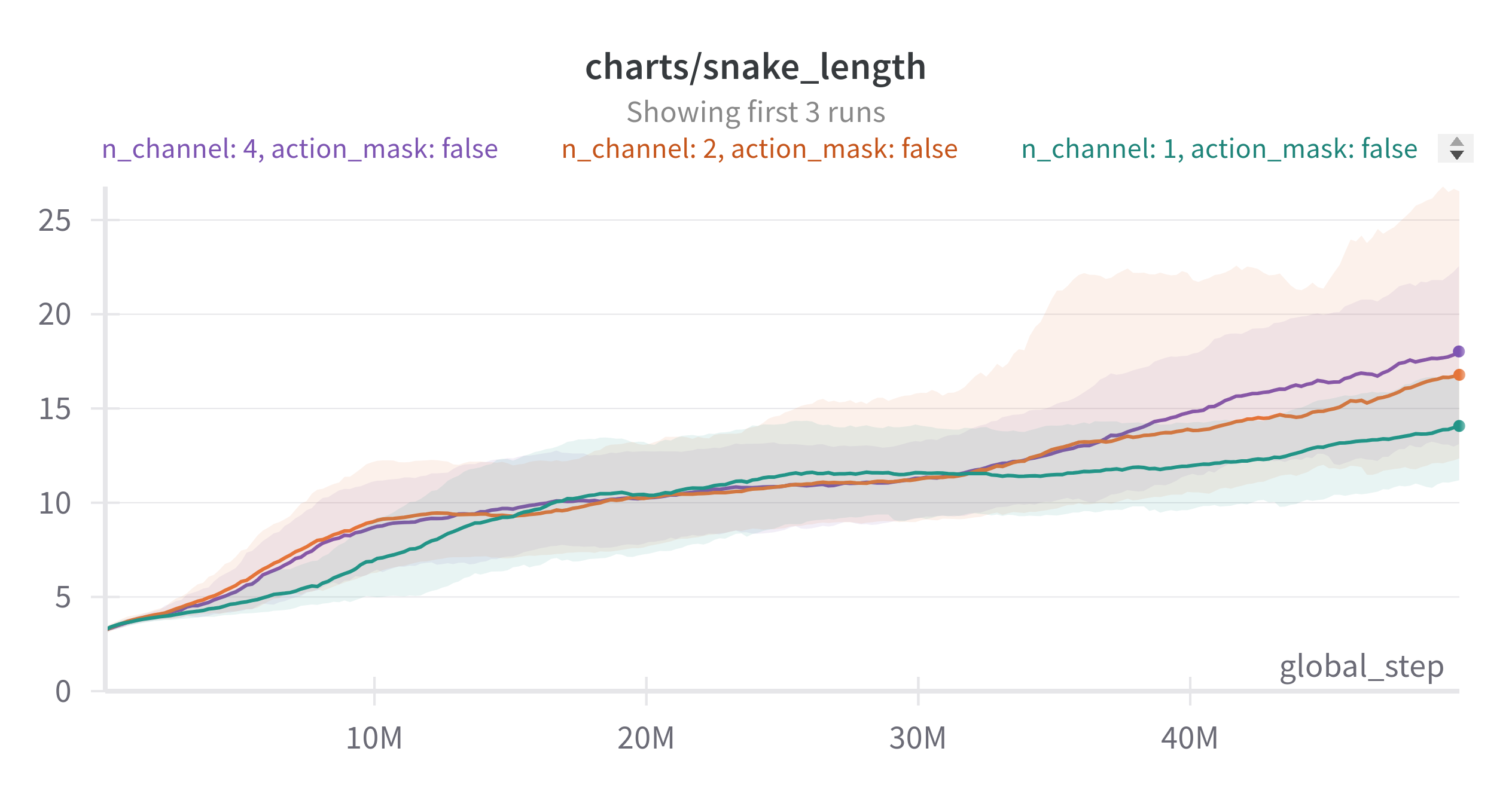
EMA: 0.9, 6 seed, board size : 12
보다시피 action masking 적용 여부에 상관없이 채널이 많을 수록 성능이 좋아지는 것을 볼 수 있다.
자세한 실험은 여기에서 볼 수 있다.
단순히 네트워크의 파라미터가 많아서 그런지에 대해서는 더 공부할 여지가 있다. 1 channel observation을 무작위로 4개로 나누어 동일한 네트워크로 구성한 후 학습 성능이 나오는지 확인할 필요가 있다.
하지만 FCN에 비해 CNN의 파라미터 비중이 적기 때문에 과연 그것 때문일까 하는 생각은 든다.
아직 실험을 해보지는 않았지만 해당 요소를 명시적으로 분리한 것이 채널간의 one-hot vector 가 되지 않았을까 하는 생각이 든다.
15. action masking 적용
관련 내용은 아래 서술하였다.