2048 게임 강화학습 도전기
2048 게임을 정복하기 위해 gym-game2048 강화학습 환경을 만들고 그것을 정복하기 위해 시도한 시행착오를 적어놓은 일지이다.
학습에 사용한 코드는 rl-application-gym-game2048에서 확인할 수 있다.
차트는 아래 링크에서 자세히 볼 수 있다. https://wandb.ai/iamhelpingstar/game2048?workspace=user-iamhelpingstar
(2023-05-19 23:43:28)
1. sparse reward vs dense reward
2048 게임의 목표는 2048이라는 숫자를 만드는 것이다. 그리고 점수는 합쳐진 숫자들의 합이다. 예를 들어 4와 4를 합쳐서 8을 만들었다면 8점이 추가된다. 또 2와 2, 4와 4를 합쳤다면 12점이 올라가게 된다. 여기서 보상을 어떻게 설정할 것인가에 대해 고민이 있었다.
게임의 목표를 2048을 최대한 빨리 만드는 것으로 한다면 점수를 보상으로 하였을 때 게임을 바로 끝내지 않고 더 점수를 얻고 끝내는 상황이 나올수 있다는 생각이 들었다. 또한 예를 들어서
1
2
3
4
5
# ex1
2 4 2 4
0 0 0 0
0 0 0 0
0 0 0 0
와 같은 상황에서 위로 올리면 블록이 새로 스폰되지도 않고 아무일도 일어나지 않으나 이것은 한 스텝에 해당한다. 이럴 경우 게임 진행이 거의 멈춰버릴 수 있다. 이를 방지하기 위해 모든 스텝에 대해 -0.001의 보상을 주고 학습을 했다. 그리고 실패, 성공 각각에 대해 -5, +5의 보상을 주고 학습을 했다.
결과는 실패였다. 원인은 다음과 같다. 스텝의 수가 일정 횟수를 넘어가면 그것이 실패의 보상인 -5보다 낮아진다. 그럴 경우 에이전트는 “기약없는 무의미한 행동을 반복할 바에는 빨리 죽어서 보상을 최대화하자” 라고 생각하게 된다.
2. truncated의 주의점
1번과 같은 이유로 TimeLimit을 이용해서 일정 횟수를 넘어가면 truncate를 했다. 이것은 무행동을 반복하고 있을 확률이 높기 때문에 그전에 끊어버리는 것이다. 이러면 경우에 따라 문제가 각각 있었다.
- 시간제한 × (step의 보상) 이 클리어 실패시 보상보다 높을 경우 (예를 들어 -0.0001 × 30000 > -5) 학습이 되지 않는다. 지정된 시간 내에 빨리 클리어를 해서 보상을 높이라는 의도였으나. 실패할바에 그때까지 최대한 버텨서 보상을 높이는 것이다.
- 시간제한 × (steps의 보상) 이 클리어 실패시 보상보다 낮을 경우 다른 관점으로 문제가 발생하는데, 스텝이 너무 높아지면 이득이 너무 낮아지므로 그 전에 최대한 빨리 게임을 끝내버리려고 하는 것이다.
TimeLimit가 효과가 없던 것은 결국 양의 보상이 너무 희소하기 때문에 벌어진 일이었다.
3. 보상 설계 변경
보상을 게임의 게임의 점수 체계와 같게 하였다. 합쳐진 블록에 각각 $\log_2$를 취하고 0.1을 곱해서 모두 더하였다. 예를 들어 4+4, 2+2가 동시에 합쳐졌다면, 8, 4가 만들어지므로 0.3, 0.2를 더해서 0.5의 보상을 받는 것이다. 로그를 취하는 것이 맞는것일까 라는 생각을 했다. 2048을 만들면 나오는 1.1과 1024를 만들면 나오는 1.0의 보상의 가치가 같을까 하는 생각이 든다. 게다가 2048을 만들면 게임이 끝나버려서 더이상의 보상을 얻지 못하게 된다.
4. 한계
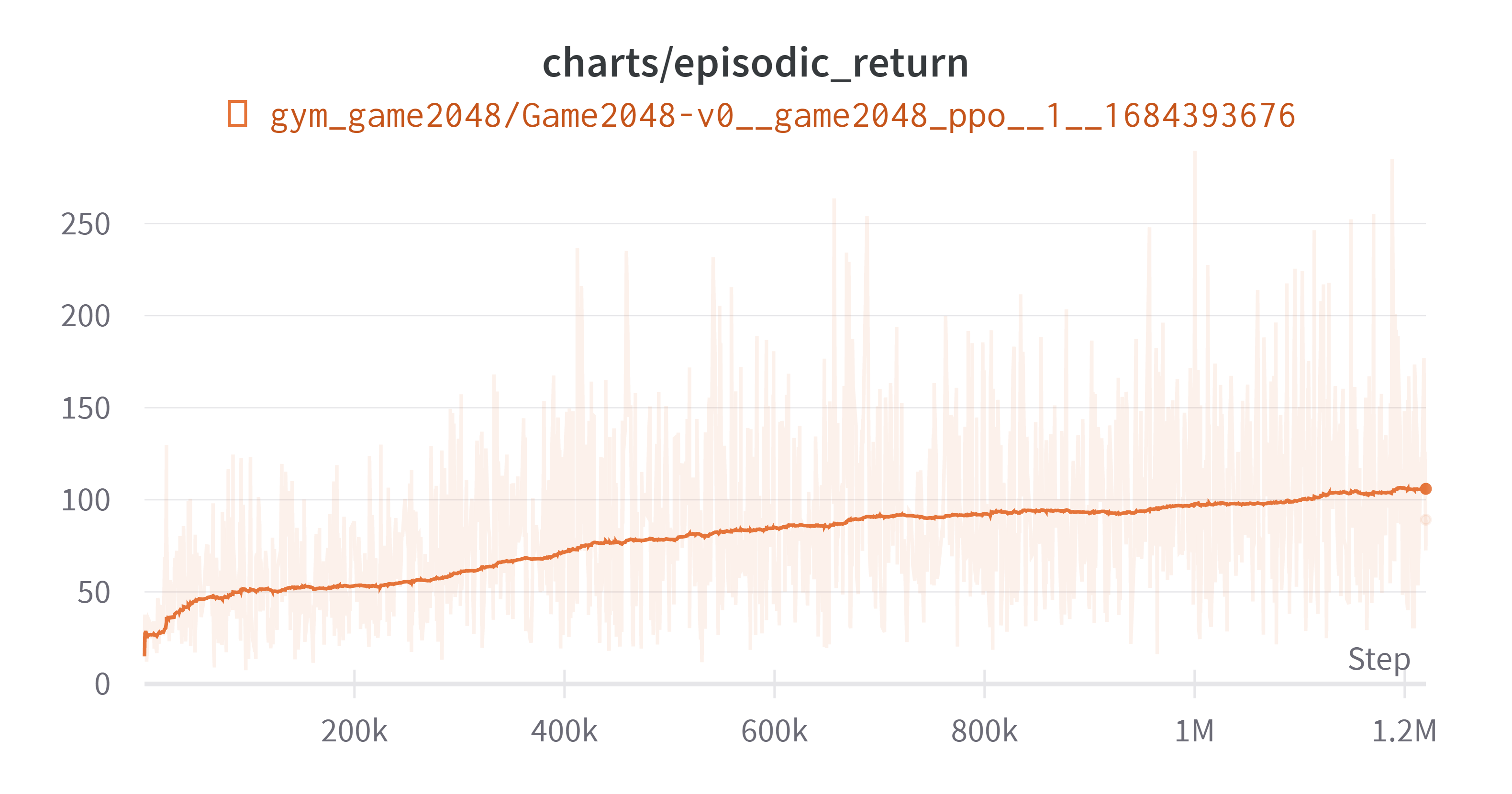
(Exponential Moving Average: 0.99)
전체적으로 상승곡선을 그리기 때문에 더 시간을 투자한다면 해결될 수도 있지만, 여기까지에 대해 세가지 개선 방안을 생각해 보았다.
- (16, 64), (64, 64), (64, ~) 로 설계된 actor, critic 신경망의 유닛 개수를 늘려 보기
- CNN을 사용해서 공간 정보를 더 얻어보기, 예를 들어 위 아래는 게임적으로 연관이 있으나 Flatten 되면서 공간 정보가 사라지게 된다.
- 마지막 클리어에 대한 보상을 더 높이기, 현재는 보상이 선형적인데 때문에 최종 보상에 대한 모티브가 부족한게 아닐까 싶다. 1, 2를 현재 실험결과와 비교해본 뒤에 시도해볼 생각이다.
(2023-05-22 12:14:21)
5. CNN의 적용
모델을 개선하기 위해 CNN을 적용시키기로 했다. 그와 함께 몇가지를 수정하였다. 수정사항은 다음과 같다.
기존
- MLP만 사용한다.
- (1, 4, 4) ⇒ Flatten ⇒ (16, ) ⇒ (16, 64) ⇒ (64, ) ⇒ (64, actor/critic) ⇒ (actor/critic)
- 활성화함수로 Tanh 사용
변경
- CNN도 사용한다.
- (1, 4, 4) ⇒ (32, 3, 3) kernel ⇒ (32, 2, 2) ⇒ Flatten ⇒ (128, ) ⇒ (128, actor/critic) ⇒ (actor/critic)
- 활성화 함수로 ReLU 사용
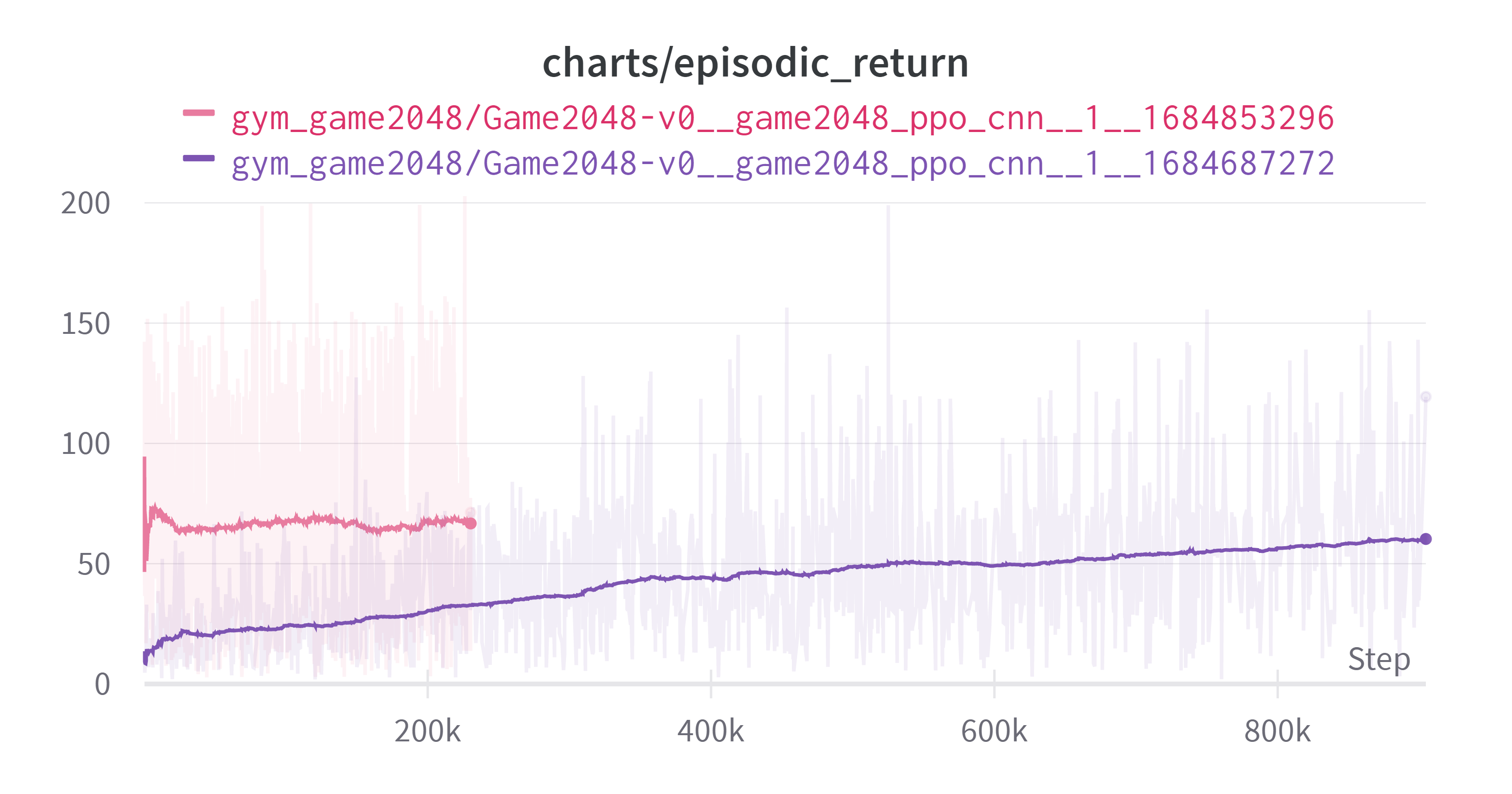
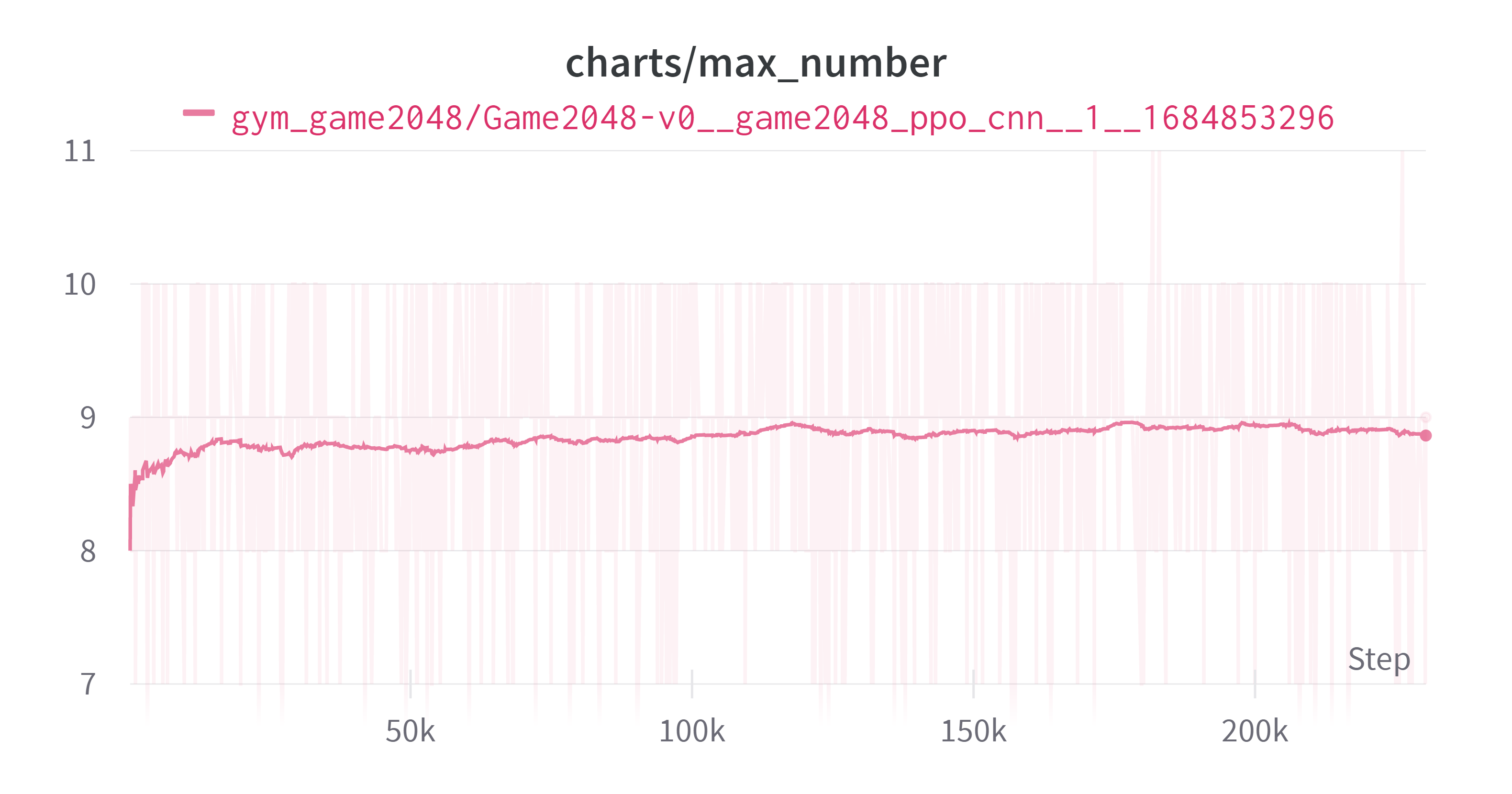
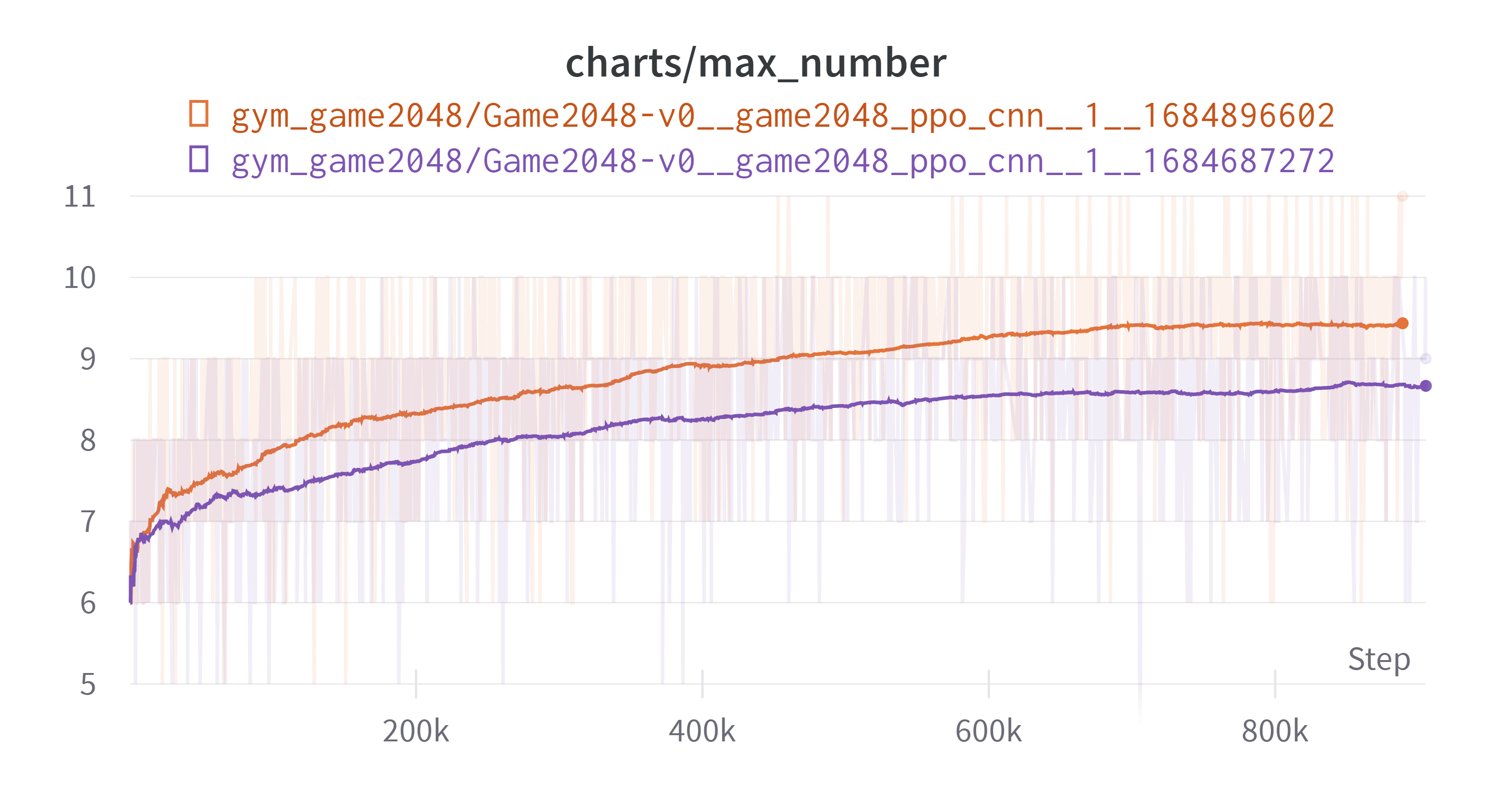
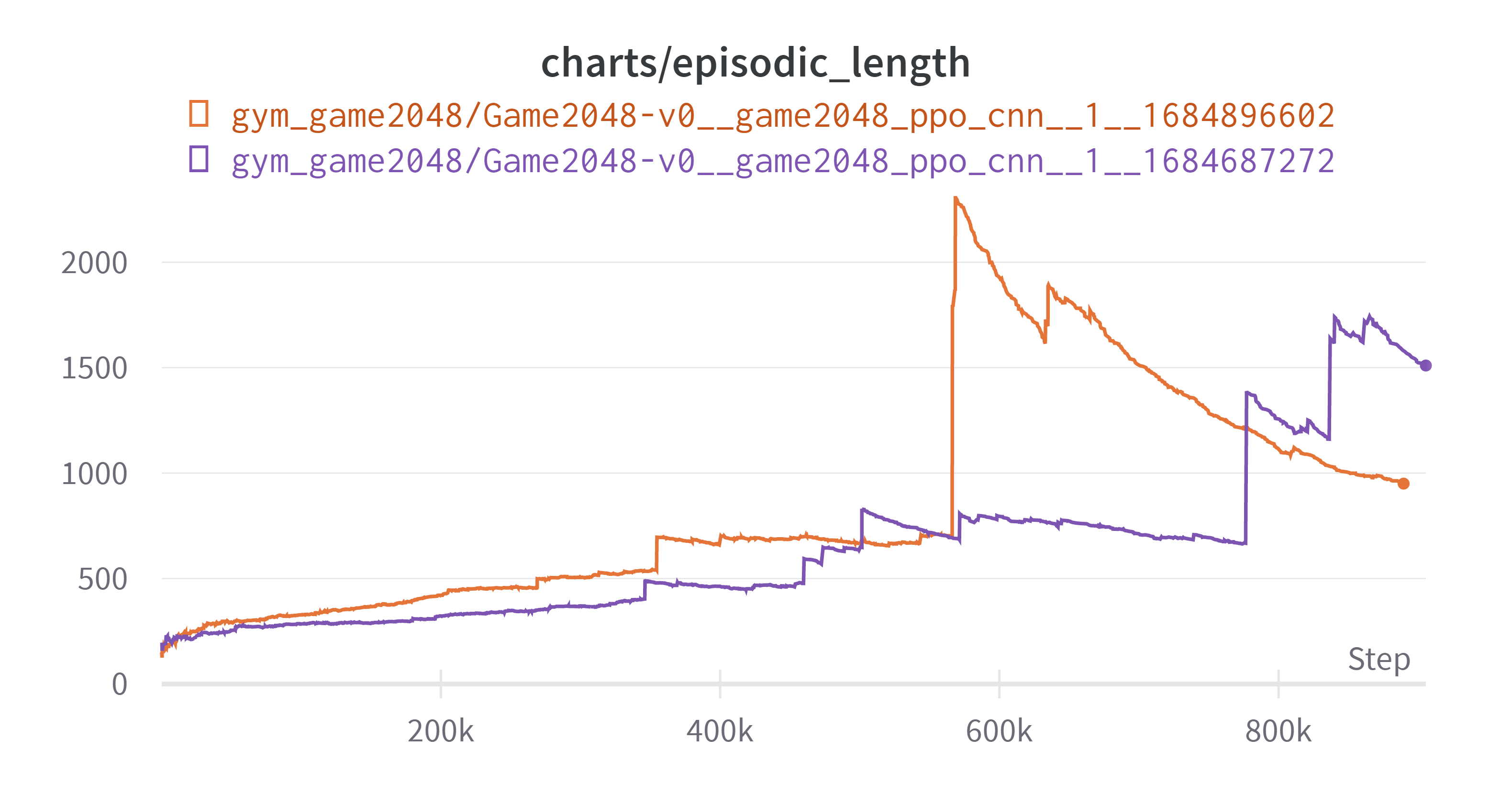
결과는 다음과 같다. 회색 그래프가 CNN이 적용된 모델이다. 결과 그래프를 보기 전에 특이(원하지 않았던)현상을 먼저 살펴보자
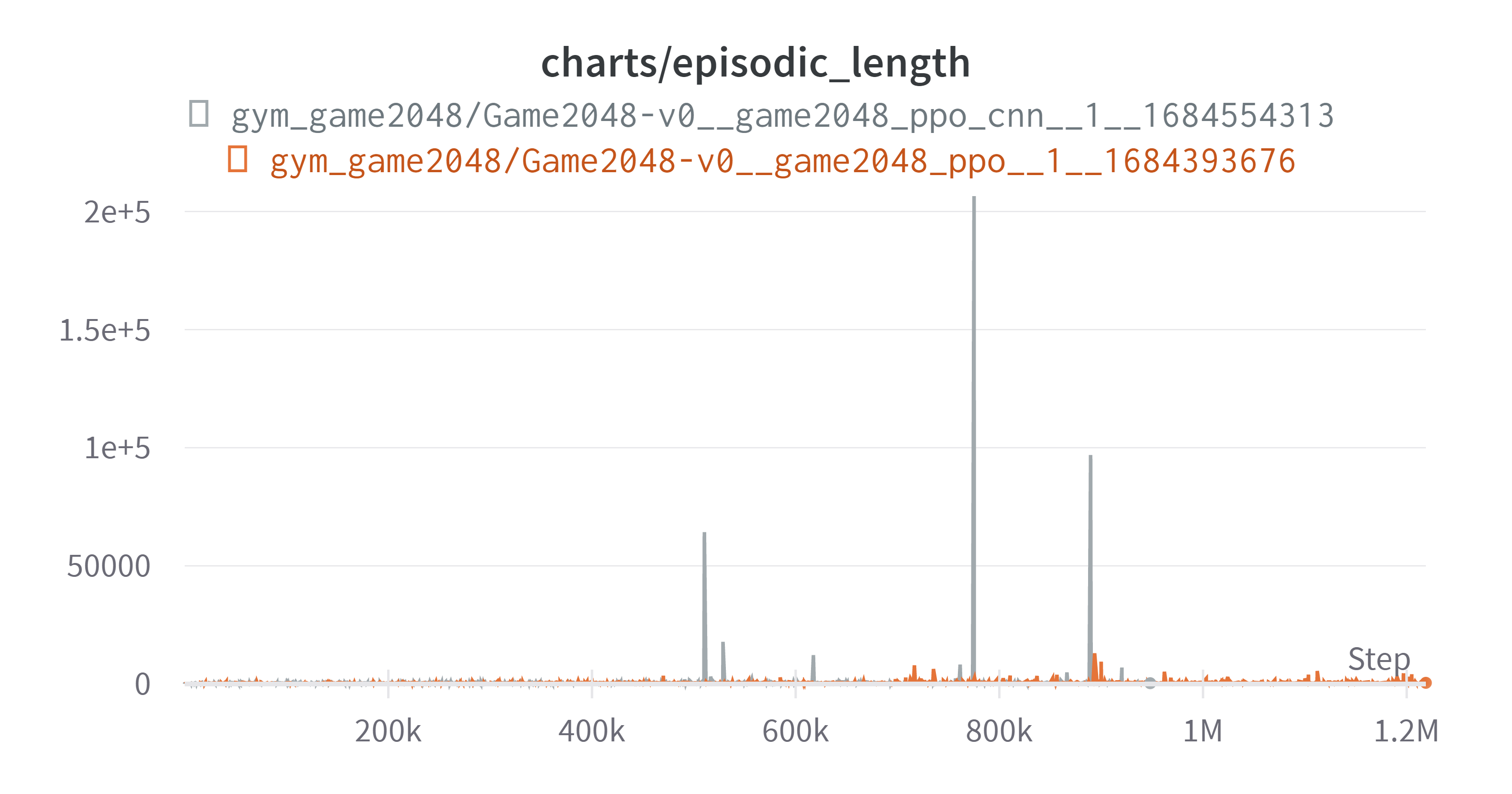
새로운 모델 적용 과정에서 한 특정 에피소드가 턱에 걸리는(필자가 만들어낸 표현, 아무의미 없는 행동을 많이 반복하는) 현상이 발생했다. 이전 모델에도 그런 부분이 있긴 했으나 지금만큼 심하지는 않았다. 이로 인해 한 에피소드에서 상당한 양의 스텝을 소비하게 되었다. 이로 인해서 그래프가 약간 이상해졌는데 이에 대해서는 뒤에 자세히 서술하겠다.
그리고 단순 턱에 걸리는 현상 때문인지 성능 향상으로 인해서 한 에피소드에 소비되는 스텝의 양이 증가했기 때문인지 모르겠지만 그로 인하여 아래와 같이 업데이트당 소모하는 스텝이 늘면서 아래와 같은 그래프가 나왔다.
그로 인하여 회색 그래프가 중간에 끊겼다. 아래는 결과이다. (exponential Smoothing: 0.99)
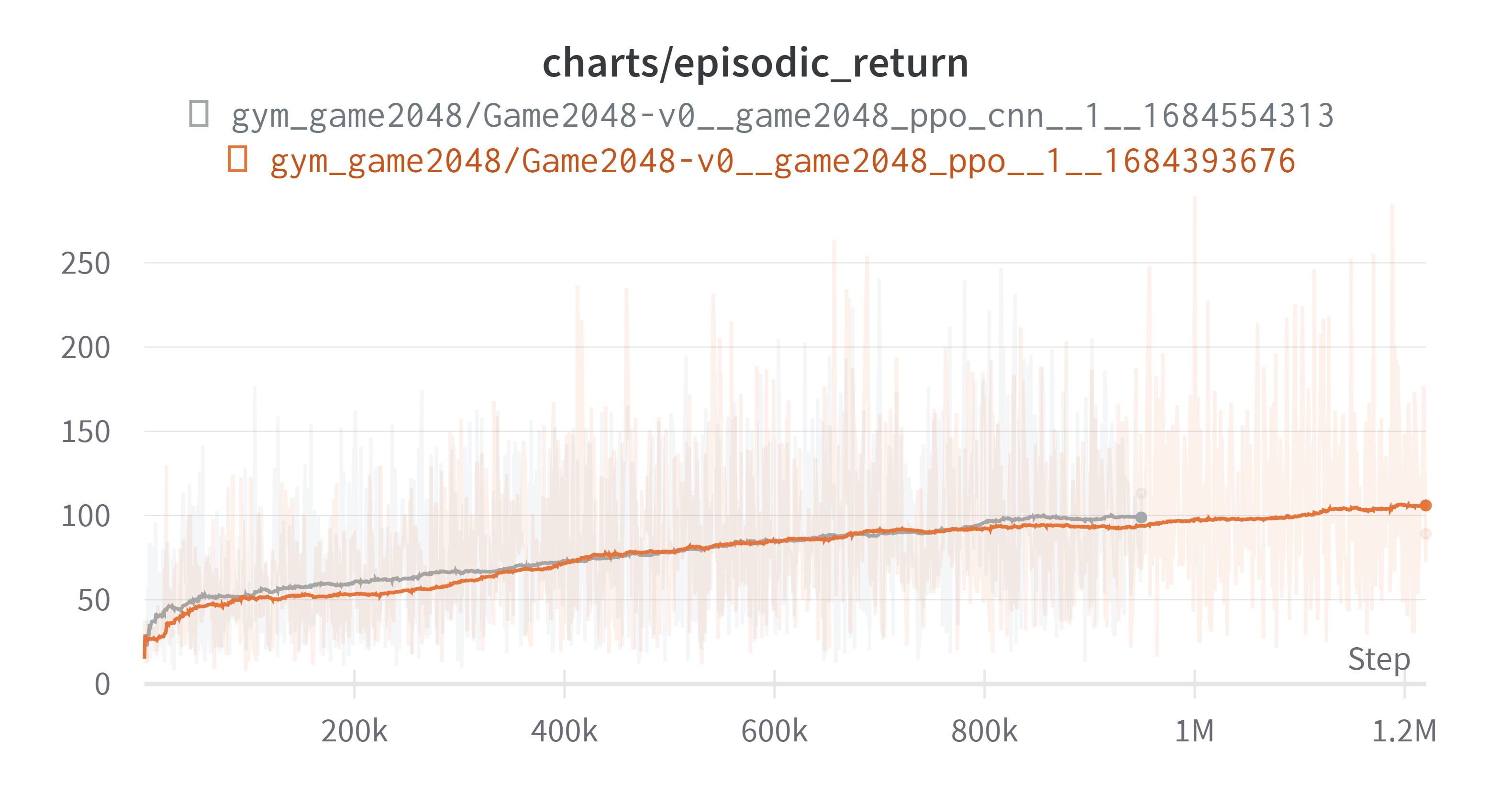
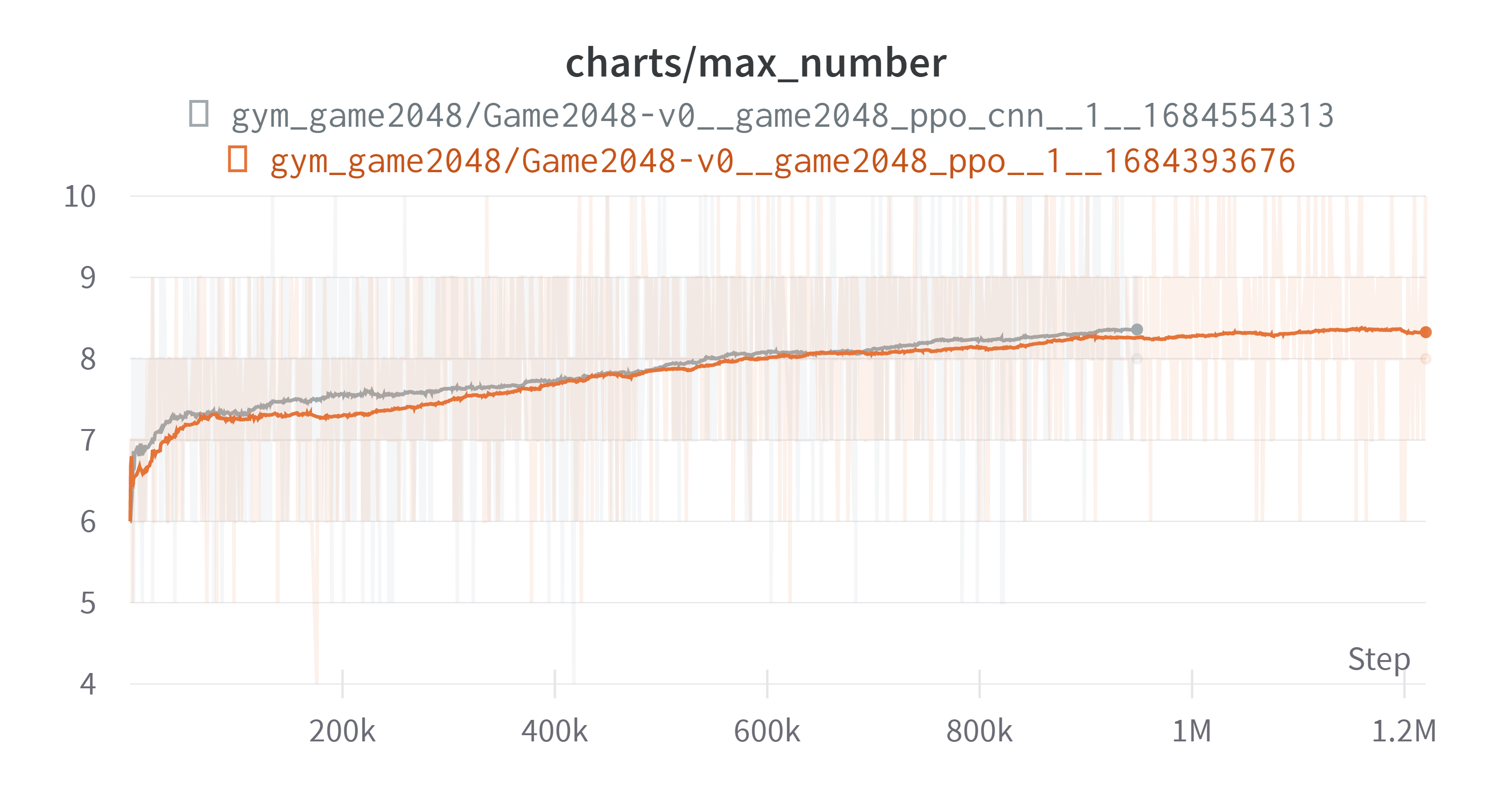
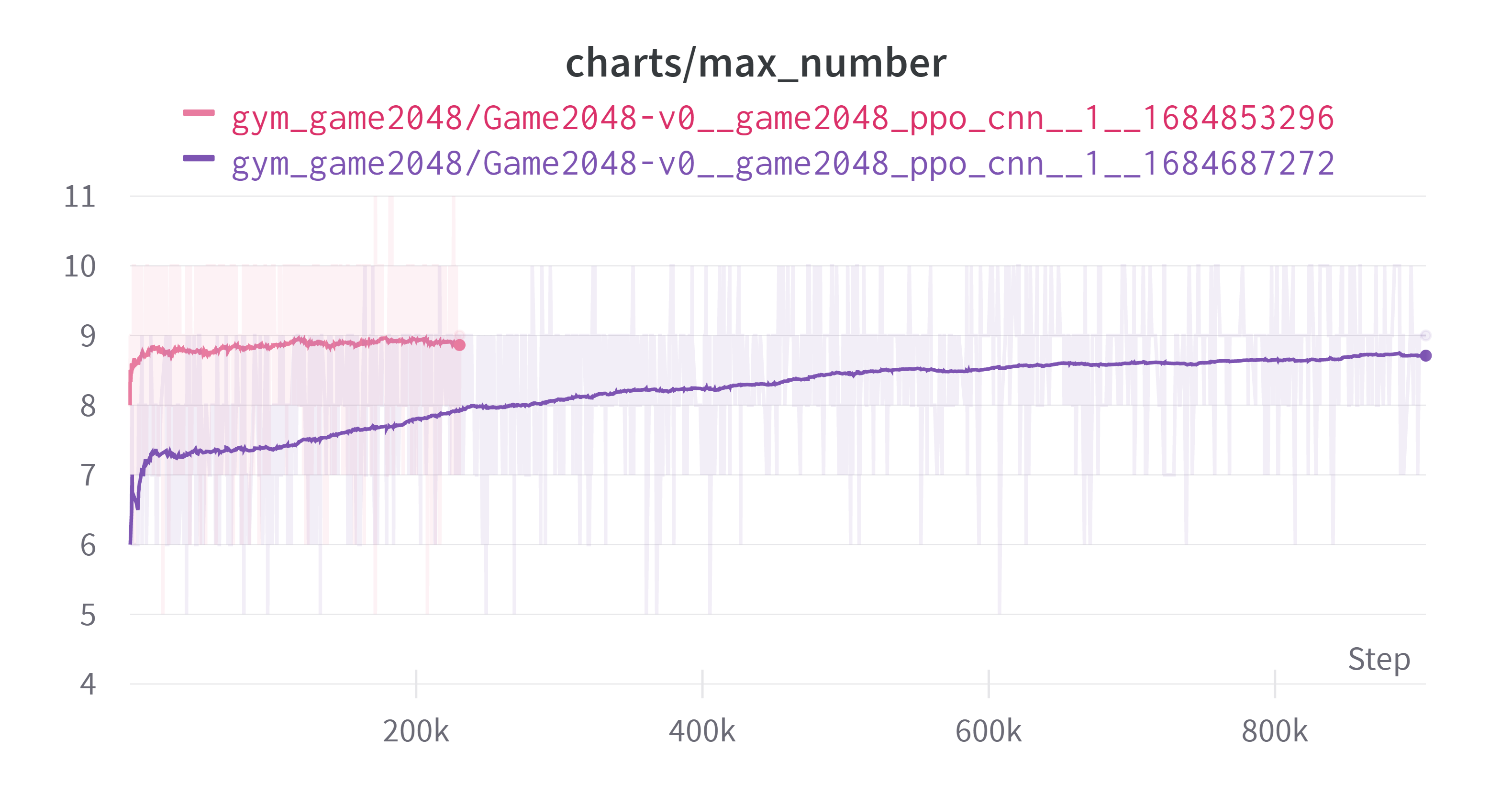
상기해보면 우리의 목표는 max_number를 최대한 크게 만드는 것이었고 그를 위해 보상을 합쳐져서 만들어진 블록에 $\log_2$를 취하고 0.1을 곱하는 것이었다. 그리하여 보상은 [0.2, 0.3, …, 1.1]을 가지게 된다. 초반 추세는 회색 그래프가 빠르지만 마무리 상태에서는 비슷하다. 무의미한 행동에 많은 스텝을 소모하게 되면서 제대로된 비교는 못하게 되었다. 하지만 여기까지의 결과에 대해 몇가지 생각을 했다. 엄밀하지는 않다.
- 늘어난 가중치 때문인지, CNN 때문인지는 확실하지는 않지만 성능의 상승을 주는 것은 맞는 것으로 보인다. 이후의 실험에서는 CNN을 사용하기로 했다.
- 턱에 걸리는 상황을 피해야 한다. 턱에걸리는 상황은 주로 다음과 같은 상황에서 나오게 된다.
1
2
3
4
5
# ex2
128 4 2 0
252 2 16 0
128 8 2 0
16 32 4 0
에이전트는 한쪽(방향은 무관한 것 같다)으로 높은 숫자를 몰아높고 하나씩 몰아주면서 점점 늘려가는 방식을 취하는데 왼쪽으로 몰아놓았다고 가정할 때 에이전트가 선호하는 방향은 왼쪽, 위쪽, 아래쪽일 것이다. 근데 위와 같은 상황에서는 왼쪽, 위, 아래가 의미없는(행동을 해도 아무런 효과가 없는) 행동이 된다. 의미있는 행동은 오른쪽으로 가는 행동인데 이것은 왼쪽에 이쁘게 모여있는 높은 숫자들의 대형을 흐트리게 된다. 높아진 숫자는 다시 모서리로 넣기 힘들다. 사람 입장에서도 기피하고 싶은 이 상황은 에이전트에게도 확률이 아주 낮게 설정되어 있어 벗어나기 아주 힘든 상태가 된다.
이런 2번같은 상황을 벗어나기 위해 해결책을 생각해보았다.
6. 턱에 걸린상태에서 넘어가기
턱에서 넘어가지 않는 상황에 대해 다음과 같은 생각을 해 보았다.
- 장기적으로는 그것이 보상이 별로라는 사실에 대해 알기 때문에 장기적으로는 기대보상이 0인 상황을 벗어나기 위해 바로 움직이게 될 것이다.
- 턱에서 벗어나려는 동기가 부족할 수도 있다. 벗어나려면 이쁘지 않지만 어찌됐든 그 상태를 벗어나야 한다. 어차피 가만히 있어봤자 보상은 0이기 때문이다.
ex2로 생각하면 오른쪽으로 옮겨야 하는 것이다. 그런데 2와 2를 합쳐서 보상을 0.2를 얻는 것과 256과 256을 합쳐서 0.8의 보상을 얻는 것이 거의 차이가 나지 않으니 더 큰 숫자를 합치는 것에 대해 동기가 부족한게 아닐까 하는 생각을 했다. - 일반적인 행동에 대해 음의 보상을 주는것은 어떨까, 성공, 실패만을 보상 설정에 이용하는 경우(보상의 희소했던 경우) step에 대해 음의 보상을 주는 것은 역효과가 있었지만, 지금과 같이 나름 학습이 잘 되는 경우 턱에 걸린 상황에서 음의 보상을 주는 것은 효과가 있을 수도 있겠다는 생각이 들었다.
- 시간 제한(TimeLimit)을 두는 것이다. 최악의 상황에서 모든 블록이 2로 스폰되었고 16칸을 모두 1024로 만들 때 무의미한 행동(아무 블럭도 움직이지 않는 행동)을 안 한다고 가정하면 1024 * 16 / 2 = 8192번의 행동이 필요하다. 그런데 심한 경우 에피소드의 길이가 10만 단위까지 넘어가기도 한다. 이럴 경우 시간 제한을 통해 truncation으로 다음 학습을 도모하는 것도 나쁘지 않을 것 같다는 생각도 든다. 하지만 그런 행동에 대해 진짜 얼마나 나쁜지 확인하기 전에 학습하기 전에 끊어버릴경우 그 것이 얼마나 나쁜지를 영영 모를 수도 있다는 생각이 들었다.
7. 보상체계 변경
6 턱에 걸린상태에서 넘어가기의 3번과 관련해서 과연 512 두개를 합쳐서 얻는 1($0.1 \times \log_{2}1024$)의 보상이 2 두개를 합쳐서 얻는 0.2($0.1 \times \log_{2} 4$)의 5배라는 것이 타당한가라는 생각이 들었다. 숫자 4를 5번 만드는 것의 보상이 1024를 만드는 것과 같다. 하지만 이를 만드는데 드는 행동은 약 2 × 5 vs 512로 약 50배가 차이난다.
보상에 $\log$를 취했던 목적은 보상의 범위를 좁히기 위함이었다. 보상의 추세가 $2^x$를 따라가니 보상의 큰 값(또는 분산)이 학습을 어렵게 하지 않을까라는 나의 추측 때문이었다.
그래서 각 보상의 체계를 노력의 정도와 같게 했다. 각 보상의 다음 단계보상까지의 행동의 횟수는 $2^n$ 의 추세를 따라가므로 보상도 그렇게 바꾸었다. 이는 결국 만든 숫자의 추세(4, 8, 16, …)와 같다. 그리하여 보상쳬계를 다음과 같이 바꾸었다.
보상 체계 변경은 RewardByScore wrapper를 이용하였다.
(이후 이 wrapper는 RewardConverter로 바뀐다, 구현내용은 같다. 2024-04-12 추가)
합쳐서 만들어진 숫자들을 $\{c_1, c_2, …, c_n\} \in C$ 라고하자, 합쳐진 것이 없을 경우에 보상은 둘다 0이다.
기존
\(R = 0.1 \times \sum_{i}^{n}\log_{2}c_i\)
- 범위 : $\left [ 0, 0.1 \times \log_{2}(\text{goal}) \right ]$
- 예시(goal=2048) : 0, 0.1, 0.2, …, 1.1
변경
\(R = 0.01 \times \sum_{i}^{n}c_i\)
- 범위 : $\left [ 0, 0.01 \times \text{goal} \right ]$
- 예시(goal=2048) : 0, 0.02, 0.04, … 20.48
(2023-05-24 15:20:46)
실험의 결과를 보자 return의 경우는 reward 산정 방식이 달라졌기 때문에 의미가 없어 제외하였다. 보라색이 새로운 결과이다.
일단 예상치 못한 변수가 있었다.
아파트 변압기 교체로 인하여 정전이 일어났다! 그래서 실험이 중간에 멈추긴 했지만 나름 진행되고 멈춰서 결과는 어느정도 확인할 수 있었다.
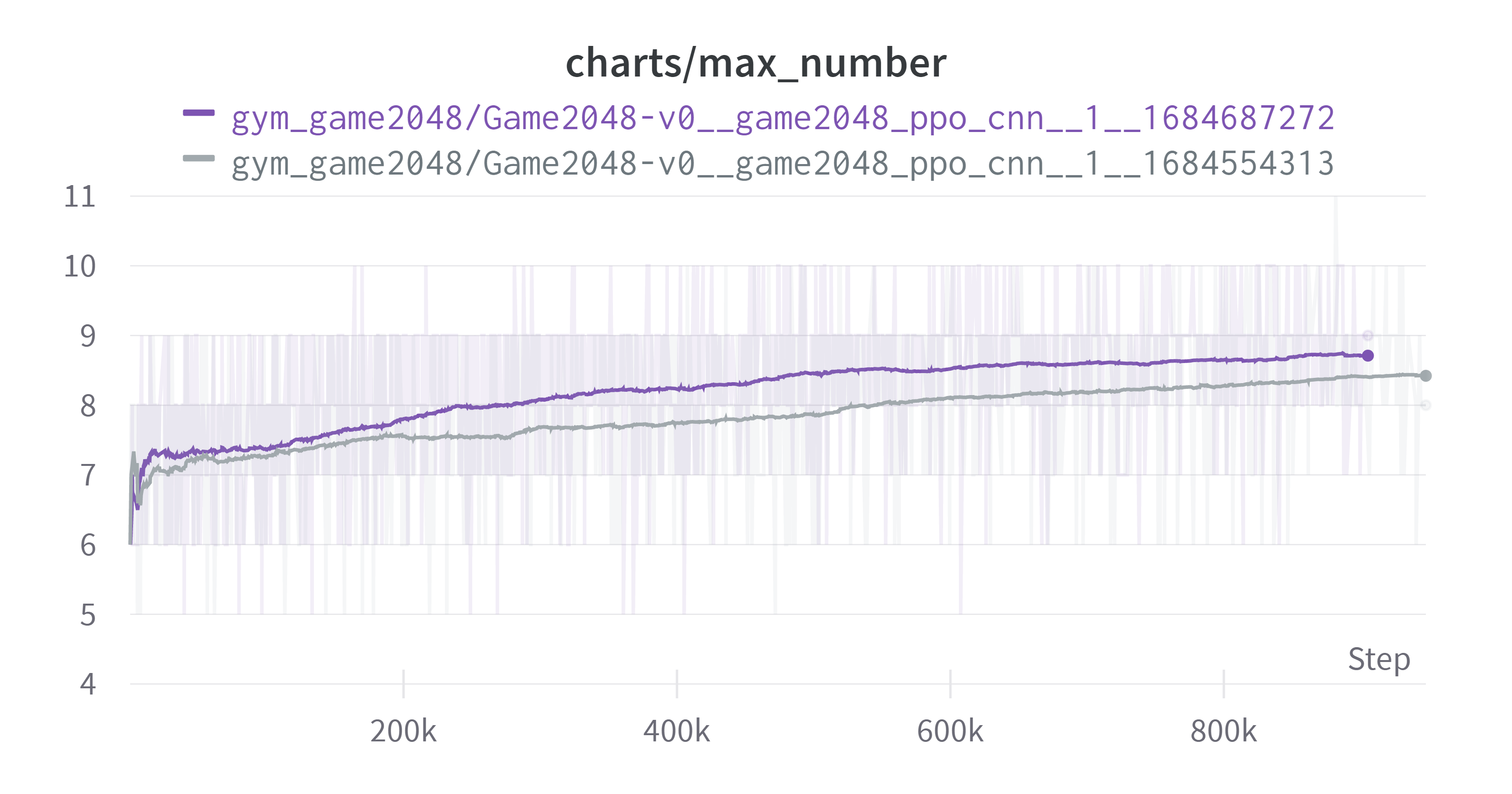
(Exponential Moving Average: 0.99)
실험의 목적인 “보드에 있는 숫자의 최댓값을 높이기, 2048을 달성하기”에 대해서는 더욱 효과가 있는 것으로 나타났다. 아무래도 노력의 추세와 보상의 추세를 동일하게 만든 것이 효과를 본 것 같다.
또한 “턱에 걸린상태를 벗어나기”, 직접적인 목표와는 관련이 없지만 학습을 효율적으로 하기 위한 것에 대해서 효과가 있었는지 살펴보자
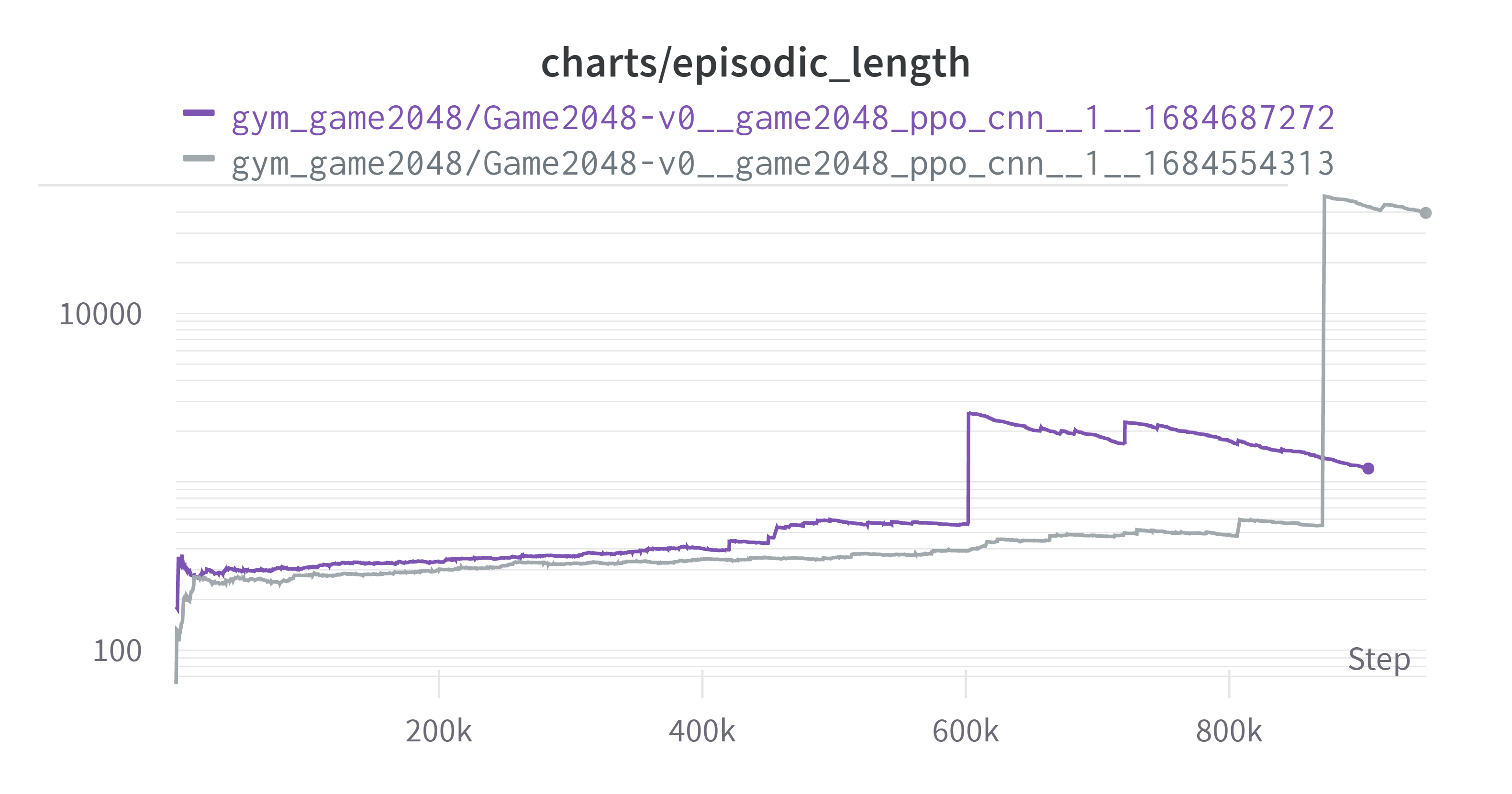
(Exponential Moving Average: 0.99, Log Scale)
이전보다 더 나아졌다고 볼 수도 있지만. 이상치를 제외한 대부분에 있어서는 새 실험이 오히려 더 에피소드 길이가 늘어났다. 성능이 더 좋아졌기 때문에 그럴수도 있지 않냐 라고 할 수 있겠지만 해당 그래프의 세로축은 로그단위인 것을 감안하면 성능 향상에 의한 효과 이상으로 에피소드의 길이가 길어졌다고 판단된다. 그러므로 단순히 보상체계 변경이 “턱에 걸리는 상태를 벗어나기”라는 관점에서는 실패한 것으로 판단하였다.
8. 이어달리기
7. 보상체계 변경 에서 정전으로 인해 실험이 끊겼다. 다행히 모델의 가중치는 일정 간격마다 저장했고 가장 최근의 가중치를 이어서 로드후에 학습을 다시 시작하였다.
분홍색이 새로운 결과이다.
(Exponential Moving Average: 0.99)
(Exponential Moving Average: 0.99)
보상 산정방식은 동일하기 때문에 return 그래프도 넣었다. 보다시피 두개 모두 이어서 하는 것 자체는 잘 되는 것으로 보인다.
(Exponential Moving Average: 0.99)
(Exponential Moving Average: 0.99)
그런데 이 그래프를 보고 더 이상 개선될 여지가 있을까? 라는 생각이 들었다. 목표에 점점 다가갈수록 경우의 수가 급격하게 늘어나기 때문에 학습이 잠시 멈춘 것 처럼 보일 수 있지만 학습이 되고 있는 것일 수도 있기 때문이다.
하지만 7. 보상체계 변경 의 실험 결과로 인해 “턱에 걸리는 현상”은 해결을 못했다는 것이 밝혀졌기 때문에 어차피 개선도 안되는 것 같은데(확실하진 않지만) 이참에 좀 수정을 해보고 다시 실험을 진행해보자는 생각이 들었다.
9. 새로운 실험 설계
그동안 의문이었던 것을 수정하고 다시 실험하기로 하였다.
기존
- 클리어시 추가 보상 없음 (20.48의 보상을 받고 종료)
- (1, 4, 4) ⇒ [(32, 3, 3) kernel] ⇒ (32, 2, 2) ⇒ [Flatten] ⇒ (128, ) ⇒ [(128, actor/critic)] ⇒ (actor/critic), MLP의 유닛을 128개로 하였다.
- 블록이 합쳐질 때만 보상을 주고 나머지는 0을 부과한다.
변경
- 클리어시 추가 보상 부과 (20의 보상을 추가로 준다.)
- (1, 4, 4) ⇒ [(128, 3, 3) kernel] ⇒ (128, 2, 2) ⇒ [Flatten] ⇒ (512, ) ⇒ [(512, actor/critic)] ⇒ (actor/critic), MLP의 유닛을 512개로 늘렸다.
- 모든 보상에 대해 -0.001 의 보상을 추가한다.
수정이 필요했다고 느낀 점은 다음과 같다.
- 내 목표는 점수를 높이는 것이 아니라, 게임의 클리어 확률을 높이는 것이다. 그런데 보상체계는 점수와 같다. 그렇다면 1024와 1024를 합쳐서 2048을 만드는 것과 같이 클리어가 가능한 순간에 다른 블럭을 합쳐서 더 큰 점수를 얻을 수 있다면 에이전트는 그것을 선택할 것이다. 512를 4개 만들거나, 1024를 두개 더 만들면 같다. 물론 discount factor 같은 것들이 그런 것들의 효과를 줄여주긴 하지만 혹시 몰라 넣었다. 20.48과 비슷한 20점을 추가로 주기로 하였다.
RewardByScore( ->RewardConverter2024-04-12 추가)를 사용하였다. - 신경망의 크기에 대한 직관, 지식이 부족하기 때문에 다른 문제들의 신경망을 참고한다. 내가 본 두 신경망은
cleanrl/ppo.py,cleanrl/ppo_atari.py두개였다. 전자는 cartpole문제에 대해 MLP(64)를 두개 사용하였고 후자는 CNN을 통과시킨 후 MLP(512)를 두개 통과시켰다. 전자의 코드를 참고하느라 MLP의 유닛을 64개로 사용하였고 그것이 부족하여 128개로 늘렸다. 그런데 2048의 문제에 대해서 observation의 경우의 수가 $11^{16}$이다. 그렇기 때문에 cartpole 보다는 atari에 가까운 복잡도라 생각하였고 MLP의 유닛을 대폭 늘렸다. atari보다는 덜 복잡하다고 생각하였고 CNN을 3개 통과한 atari코드에 비해 CNN을 한개만 통과시켜 가중치 개수는 그보다 적게 하였다. - gym(gymnasium) 환경 구성시 고려할 점 에서 적기도 하였는데, 할수 있는데 못하는 행동(바둑에서 이미 돌이 있는 곳에 돌을 두는 행위같은 것)에 대해 고민이 많았다. 최근에 알게 되었는데 이런 행동을 illegal action이라고 한다. gymnasium에 구현된 환경들은 이런 illegal action이 없었다. 그러다가 멀티 에이전트 환경을 모아놓은 PettingZoo을 보았다. illegal한 행동을 할 경우 -1의 보상과 함께 게임을 종료(좀 심한 것 아닌가?)시키는 Chess/Legal Actions Mask가 구현된 것과 illegal action이 들어오면
illegal_reward와 함께 게임을 종료시키는 TerminateIllegalWrapper 를 보니 illegal action 에 대해 강경(?) 하게 대처하는 것을 확인할 수 있다. 두 플레이어가 있어서 legal action을 하는 것이 중요한 상황은 아니니 게임을 종료시키기는 좀 그렇고 전체 step마다 -0.001의 보상을 추가하기로 했다. illegal 한 행동을 검출하여 해당 행동에만 음의 보상을 줄 수도 있었지만 다른 reward가 0.001에 비해 충분히 높기 때문에 그냥 빼기로 했다.
10. 바보야, 문제는 신경망이야!
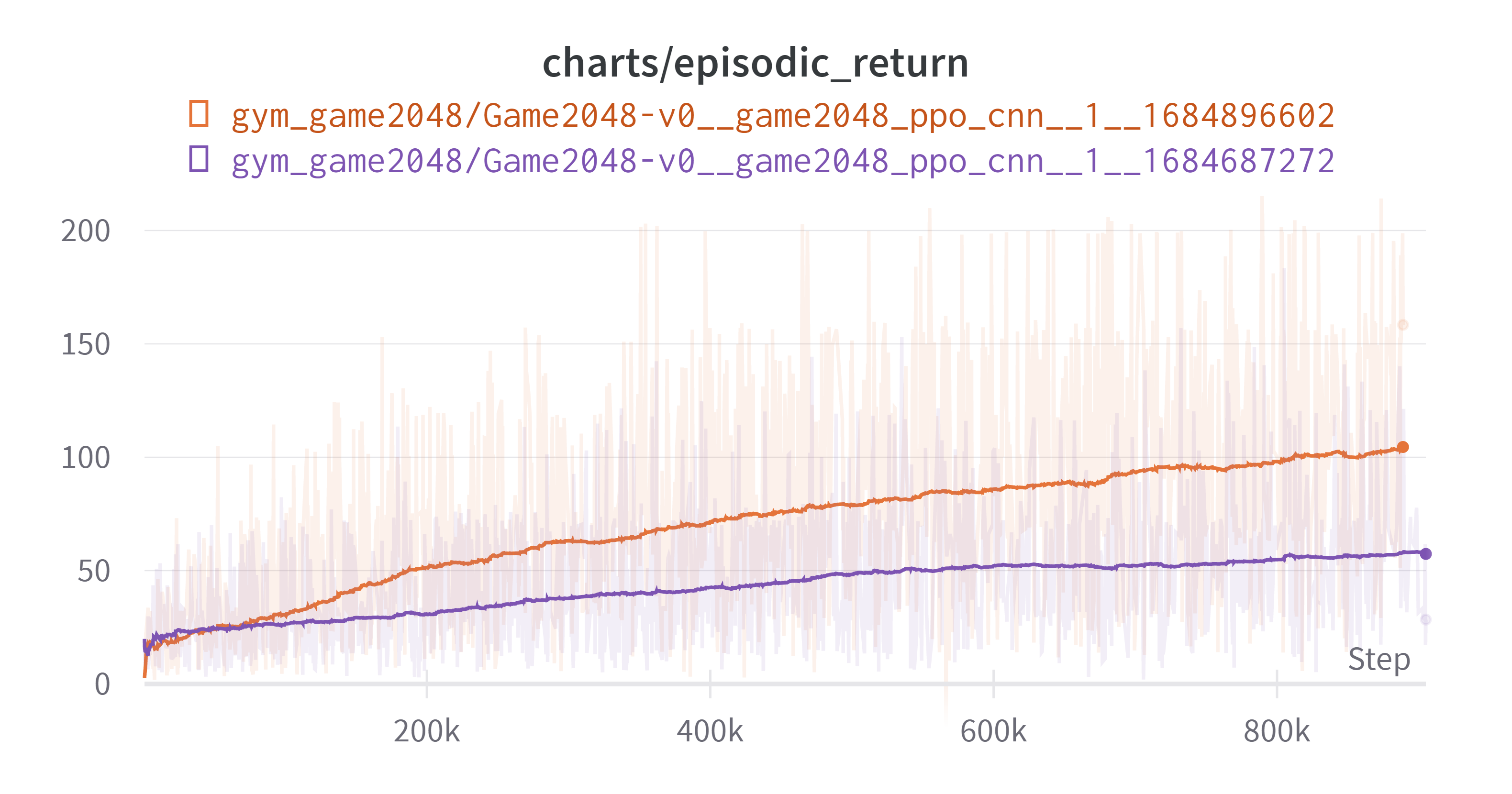
실수로 실험을 끊어버리긴 했지만 그전 실험과 비교해 유의미한 결과가 나왔다. 차트를 직접 보면 직관적으로 이해가 갈 것이다.
주황색이 9번을 적용한 새로운 결과이다.
(Exponential Moving Average: 0.99)
(Exponential Moving Average: 0.99)
(Exponential Moving Average: 0.99)
압도적으로 성능이 좋은 것을 확인할 수 있다. 시간적 한계로 인하여 개선점 세 개를 한번에 적용하였지만 몇가지 결론을 얻을 수 있었다.
- episodic length 그래프를 보면 ‘턱에 걸리는 상황’을 억제하는 데는 효과가 크지 않은 것을 볼 수 있다. 물론 성능이 증가했기 때문에 그럴 수 있지만. 전체적인 억제 효과는 미미했던 것 같다. 물론 학습이 지속된다면 점점 억제되는 효과는 있지 않을까 싶다.
- 목표(11)에 도달하면 추가적인 보상을 주었는데 도달하기 전에 이미 전 실험결과를 뛰어넘었다. 그럼 9.1처럼 성공시 보상 추가에 대한 효과 덕분은 아니라는 뜻이다. 그래서 전반적인 성능 향상은 신경망의 크기 증가 덕분이라고 결론내렸다.
- 성공시 보상 추가에 대한 것은 해당 파라미터만 조절후 다시 도전해보는 것이 좋을 것 같다.
(2023-05-27 18:39:21)
11. 모로 가도 서울만 가면 안된다.
학습된 에이전트의 플레이 영상을 보다가 든 생각이다. 먼저 그림을 보자

내가 원하는 상황은 오른쪽이다. 2048을 완성하는 것이다. 나는 7. 보상 체계 변경 에서 점수와 보상체계를 같게 했다. 그러면 실제 점수와 받는 보상의 상대관계가 같다는 이야기이다.(물론 discount factor, GAE등의 요소들이 있기 때문에 1:1로 비교하기에는 무리가 있다.)
그런데 사진을 보면 오른쪽을 지향하는데 불구하고 점수는 거의 차이가 나지 않는다. 물론 이런 상황을 충분히 예상해서 # 9.1에서 클리어시에 보상을 20을 더 줬고 이는 점수로 환산하면 2000에 해당하는 값이다. 에이전트는 클리어시에 40.24의 값을 받고 종료하기 때문에 충분히 큰 값이라 생각했다.
현재 학습의 척도는 점수이고 직접 찾아보지는 않았지만 클리어시보다 비 클리어시에 점수가 더 높은 상황이 충분히 많이 발생할 수 있다는 생각이 들었다. 그럴 경우 에이전트는 클리어가 가능한 상황에서 클리어를 하지 않고 점수를 최대한 올리는 상황을 선택할 수도 있다. 2048을 달성하기 위한 최소점수를 계산해보면 새로운 블럭이 4만 나오는 경우에는 18432, 2만 나오는 경우는 20480이다.
클리어 보너스를 왜 진작 높은 값으로 하지 않았냐에 대해서는 reward가 너무 커질 경우 학습이 안정적이지 않을 우려가 있어서였다. 근데 다시 생각해보니, 클리어는 진짜 최종 목표인데 충분히 큰 값으로 해야하나 하는 생각이 들었다. 지금 하고 있는 학습이 끝나면 클리어시 보상을 더 높여볼 생각이다.
바로 클리어를 하지 않는 상황의 예시는 다음과 같다. 윗 내용 작성중에 발견하였다.

스텝이 1차이나는데 903 스텝에서 바로 클리어를 할 수 있지만 점수를 더 얻고 끝내기 위하여 위로 옮겨서 4점을 더 얻은 다음 905스텝에서 2048을 만들고 클리어한다. 여기에 대해 몇가지 생각이 들었다.
- 최대한 빨리 클리어 하는 것이 목표라면 이것은 잘못된 행동이다. 그런데 나는 일단 클리어를 목적으로 하였기 때문에 수정하지는 않았다.
- 위로 올리는 행동을 하더라도 2048을 만들 수 있다는 것을 알고 행동을 했다면 바람직한 행동이라고도 볼 수 있다.
- 904 스텝에서 아래로 내린 후에 오른쪽으로 옮긴다면 더 큰 점수를 얻을 수 있지만 그렇게 하지는 않았다. 학습이 덜 된 것인지 알고리즘 설계상 그것이 더 높은 가치가 있었는지 낮은 확률이었는데 되었는지는 모르겠다.
PPO의 보상추정이랑, 행동 선택 이유를 추적하는 방법을 공부해야할 것 같다.
(2023-05-29 15:48:37)
12. 에이전트의 영리함
에이전트는 현재까지는 11. 에 나온 그림처럼 위쪽으로 갈수록 높은 숫자, 그리고 위쪽에서 오른쪽으로 갈 수록 높은 숫자를 만들려고 한다. 이렇게만 순항한다면 게임을 클리어하지만 변수가 있는데 다음과 같은 경우다.

위와 같은 경우는 인위적으로 왼쪽 위를 채울 수가 없으므로 우연히 왼쪽 위로 블록이 생기지 않는다면 언젠간 왼쪽으로 옮기는 행동을 해야 한다. 왼쪽으로 옮겼을 때 오른쪽 위에 블록이 생기지 않으면 좋겠지만 다음과 같이 생길 경우가 있다. 이럴 경우는 게임 클리어에 방해되는데 왼쪽부터 오름차순으로 올라가면서 블록을 합치면서 클리어해야 하는데 그때 이용할 수 있는 블록이 줄어든다.
1
2
3
4
5
6
7
# case 1)
32 64 128 256
...
# case 2)
64 128 256 2
...
각 케이스에서 아래의 블록들을 스폰하고 합쳐가면서 위쪽으로 점점 올라간다.
case 1) 에서는 256을 (한번에 다다닥) 만들기 위해 3가지 숫자를 사용할 수 있지만 case 2) 에서는 두 가지 밖에 사용하지 못한다. 오른쪽의 2가 있지만 이것은 효율성이 매우 떨어진다.
그러면 에이전트는 오른쪽의 숫자를 없애려고 할 것이다. 이전 상황에서는 이런 상황의 “턱에 걸리는” 상황의 원인이 되기도 하였다.
(물론 턱에 걸리는 상황은 이것 처럼 ‘덜’ 좋은 상황보다 완벽한 상황에서 포기해야 하는 ‘완전’ 좋은 상황에서 더 많이 발생하긴 한다.)
그럼 충분히 학습된 에이전트는 이런 상황을 어떻게 벗어나려고 할까

게임을 진행하다 왼쪽과 같이 가장 높은 숫자의 아래로 모두 다른 숫자가 나올 때가 있다. 그리고 맨 오른쪽의 아랫부분에 빈 공간이 있을 경우 아래로 내려서 박힌 숫자를 빼낸다.
이때 빈 공간중에서 블록이 무작위로 스폰될텐데 초록색과 같이 다른 공간에 블록이 스폰되면 성공이다. 물론 블록이 오른쪽 위에 다시 스폰될 수도 있다. 계속 박혀있는 것보다는 나으니 밑져야 본전인 도박을 하는 것이다.
(2023-05-30 18:20:06)
13. 용서해줘 다음부터 잘할게
예상치 못한 버그가 발생하였다. 설명하면 다음과 같다.
턱에 걸리는 상황을 방지하기 위해 9. 새로운 실험 설계 에서 0.001의 보상을 뺐다. 그런데 다음과 같은 상황이 일어났다.
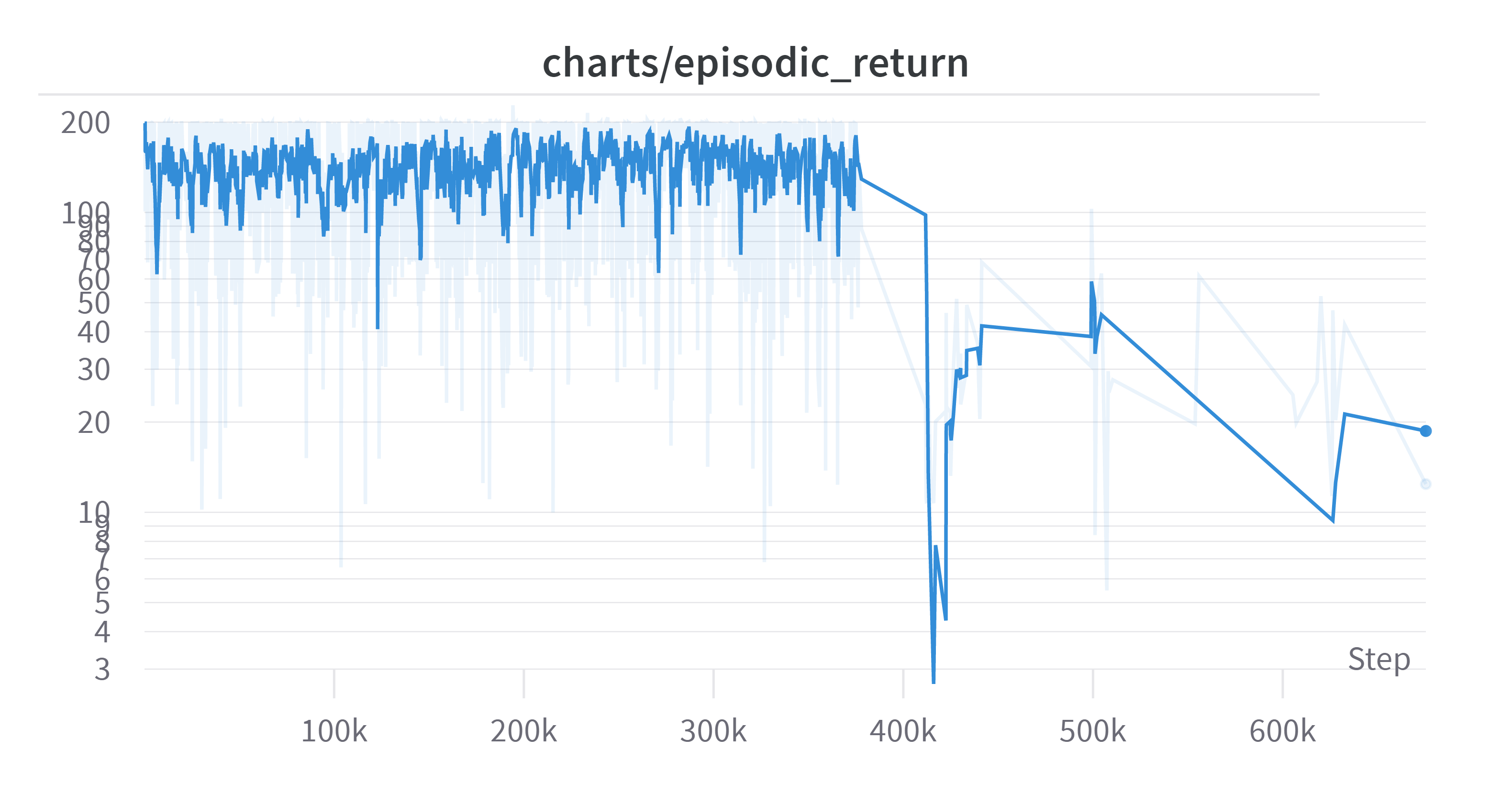
(Log Scale, Exponential Moving Average: 0.5)
갑자기 Return이 급락해서 다른 그래프를 보니 다음과 같았다. 300K 이후부터 확대해 보았다.
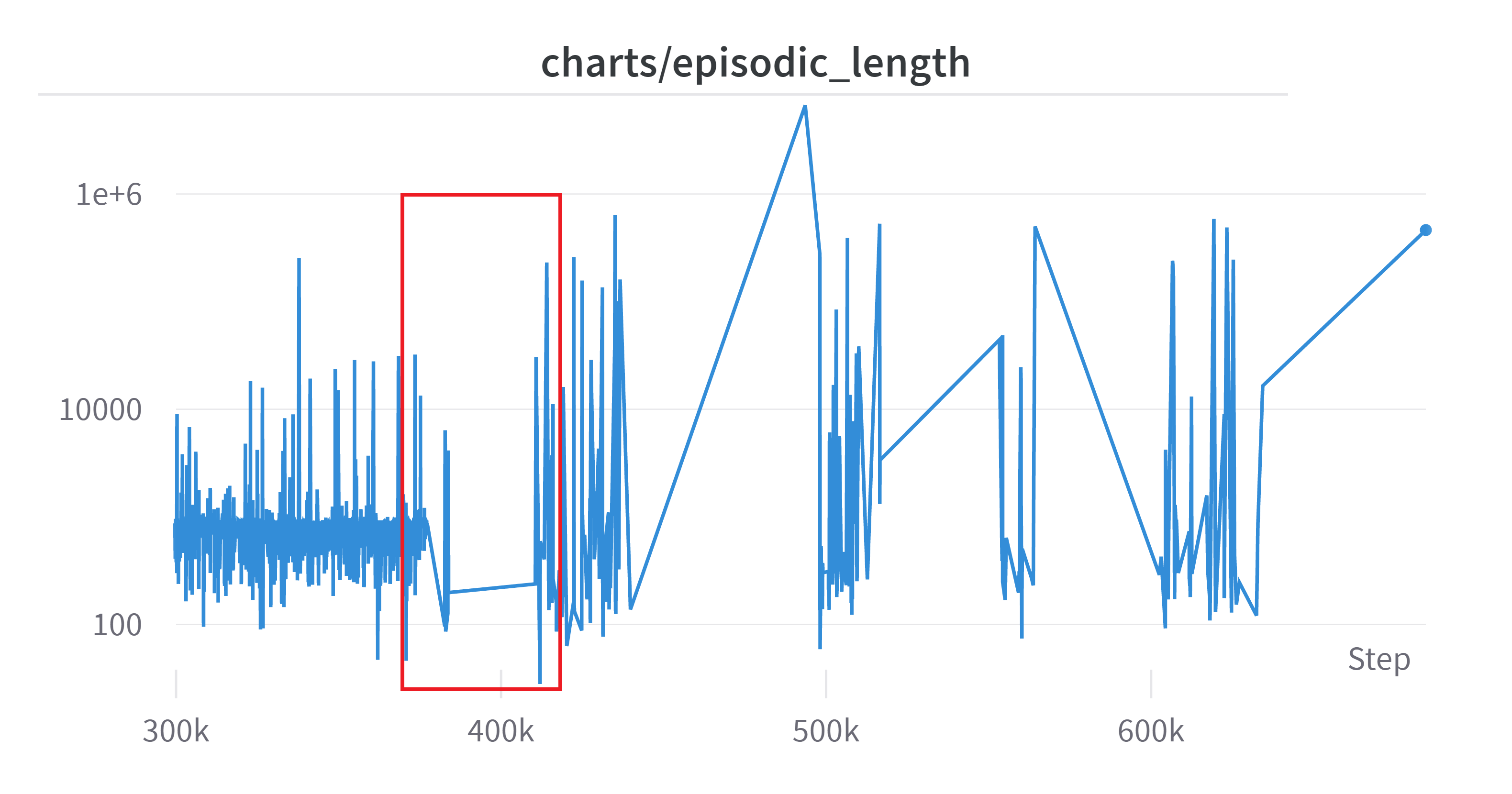
Log Scale, No discounted
빨간 부분이 episodic_return 그래프에서 400K 쯤에 밑에서 뚝 꺾이는 부분이다. 이전은 학습이 잘 되는가 싶더니 저 부분 이후로 return이 급락하였다. 그래프가 일자인 이유는 에피소드가 끝날 때마다 업데이트 하게 되는데 에피소드가 끝나지 않고 한참 있다 끝나게 되어서 step 마다 값 갱신이 되지 않은 것이다.
(2023-06-15 추가) 그래프가 일자인 이유는 위의 이유도 있지만 큰 이유는 wandb의 한 metric에 100K 이상의 스칼라를 누적했기 때문이다. 관련하여 wandb 사용시 주의할 점에 서술하였다
그리고 이후 그래프를 보면 알 수 있다시피 학습 자체가 완전히 망가졌다
해당 시간에 나온 값들을 살펴보면 다음과 같다.
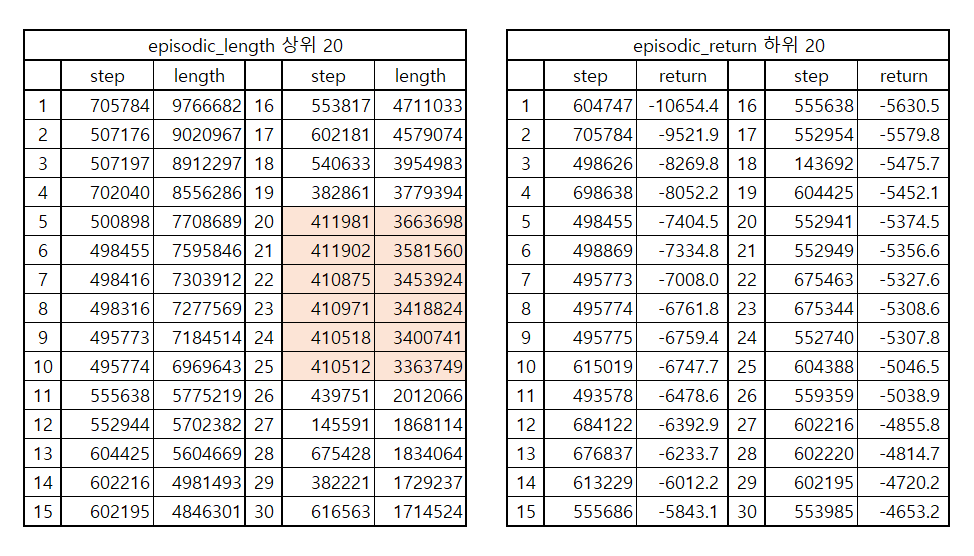
확실히 350K~420K 부분에서 “갑자기” 엄청난 시간을 소모했고 그것으로 인하여 episodic_return 또한 엄청난 음수값을 가진 것을 볼 수 있다. 그 뒤에서도 발산하면서 학습이 망가진 것을 볼 수 있다. 한 에피소드의 길이가 엄청나게 늘어나는 것을 볼 수 있다.
내가 생각하는 학습의 흐름은 다음과 같다.
- 일단 해당 학습은 그전에 학습된 weight를 이어서 학습한 것이다.
- 이전에도 비정상적인 episode_length 가 있었을 것이다.
- 하지만 학습이 진행되면서 근사의 정확도가 높아졌고 어떤 행동에 대한 확률이 상당히 높게 측정되었을 것이다. (PPO, Policy-based)
- 어떤 상태에서 해당 행동을 엄청나게 시도했을 것이다. 하지만 해당 행동은 Illegal Action이었다.
- 3M의 step동안 -0.001의 보상만 계속 받았을 것이고 discount 없이 누적된 return은 엄청난 음수를 만들었다. 이렇게 엄청나게 오랜 시간동안 의미없는 행동에 대해서 음의 보상만 계속 주어지고 그것의 한도가 없으니 (양의 보상은 그전에 클리어가 되기 때문에 한계가 있다, episodic_return(discount 되지 않고 누적된 보상의 합)의 최대값은 254이었다.) 신경망을 망가뜨렸다.
- 망가진 신경망이 복구가 되지 않고 이후로 회복이 되지 않아 계속해서 학습을 망가뜨렸다.
이것으로 느낀 것은 다음과 같다.
- 생각보다 Illegal Action에 소비되는 step 수가 많다.
- episodic_length 표의 숫자들을 보면 알겠지만 엄청난 스텝이 의미없는 행동에 소요되고 있었다.
- Illegal Action 행동에 대해서는 Terminate 하는 것이 무조건 나은 것 같다. (-> 이후 action masking을 통해 생각이 또 바뀐다, 17. action masking 적용, 2024-04-12 추가)
- Return의 하한선도 생각해야겠다. 물론 PPO가 MC 기반의 방법은 아니지만 전체적으로 분산을 높이는데 일조한 것 같다.
(2023-06-01 21:36:18)
14. 개선된 결과
★★13. 후에 Illegal Action을 적용하면서 게임 로직을 개선하였고 그 과정에서 중대한 버그가 있었다. “14. 개선된 결과” 내용은 잘못된 환경에서 실험된 결과이므로 완전히 잘못된 결과, 실험이다. 하지만 필자의 반성을 위해 남겨둔다.★★
결론적으로 엄청난 개선이 있었다.
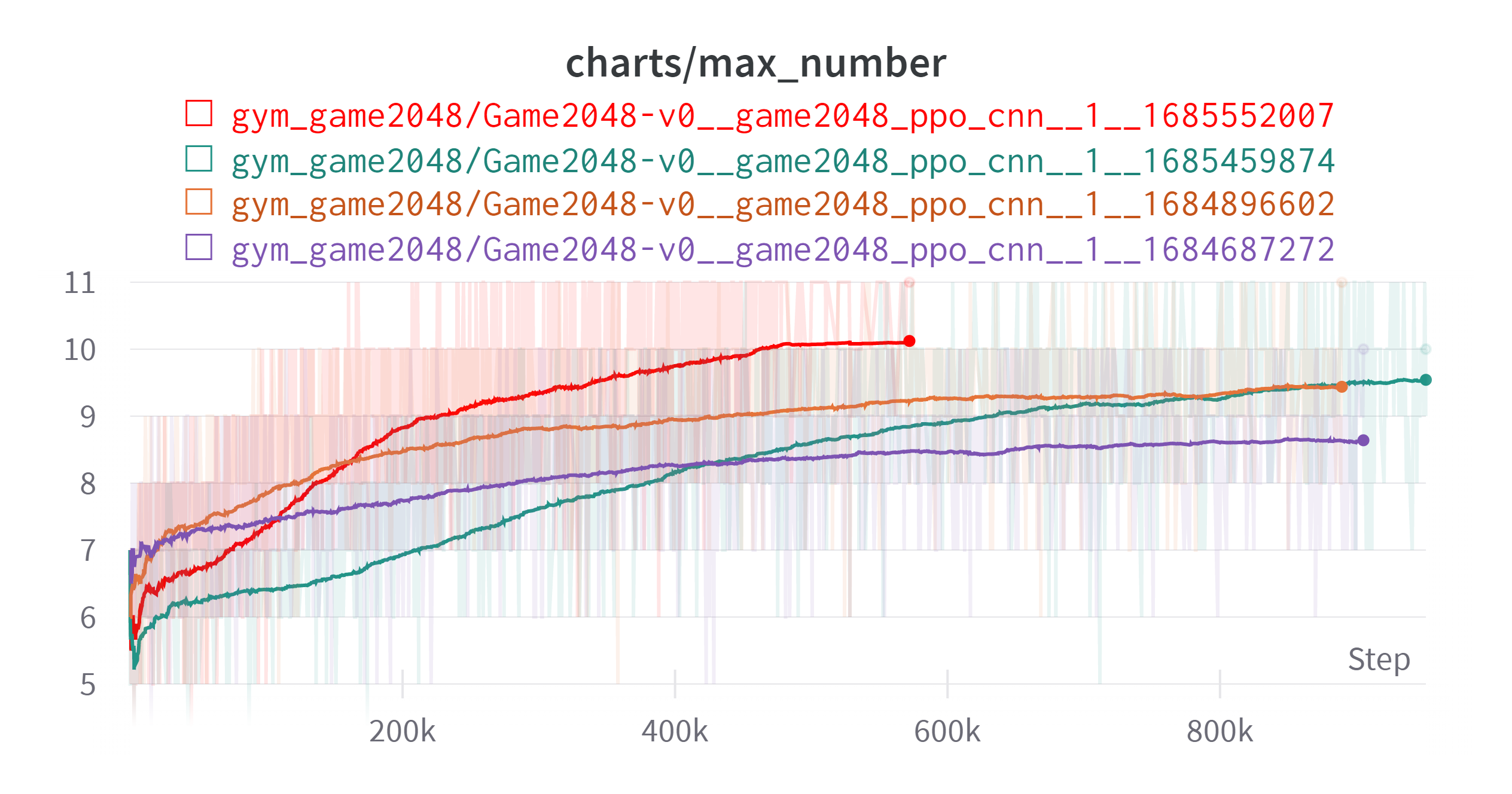
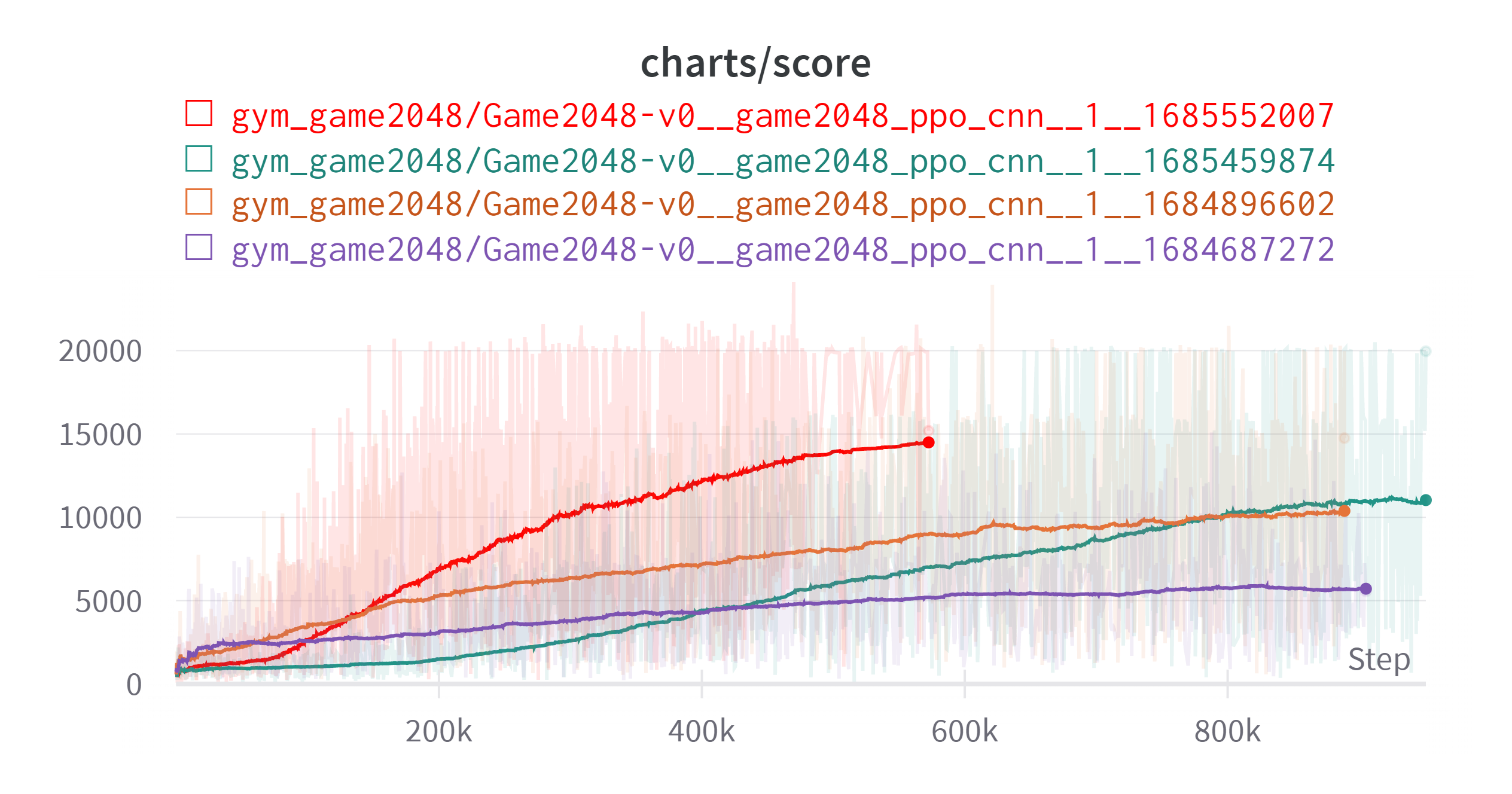
Exponential Moving Average: 0.99
플로팅에 스텝이 반영되지 않아 설명을 덧붙인다. 빨간색, 청록색이 새로 한 결과이다. 세부사항은 아래와 같다.
| 색 | time step | Linear | Illegal Action | Anneal LR |
|---|---|---|---|---|
| 빨강 | 250M | 512 | False | True |
| 청록 | 300M | 512 | False | False |
| 주황 | 500M | 512 | True | False |
| 보라 | 500M | 128 | True | False |
빨강과 청록의 차이가 있는데 자세한 보상 설정은 다음과 같다.
| 색 | 블록 합칠 때 | Illegal Action | Clear | 범위 |
|---|---|---|---|---|
| 빨강 | × 0.0025 | -5 | 5 | [-5, 10] |
| 청록 | × 0.01 | -0.2 | 0.2 | [-0.2, 20.68] |
청록색의 보상설정이 이상할 수 있는데 Wrapper 설정중에 실수가 있었다. 그런데도 이전 결과를 따라잡은 것을 보면 Illegal Action시 바로 게임을 종료시키는 것이 효과가 있었던 것 같다.
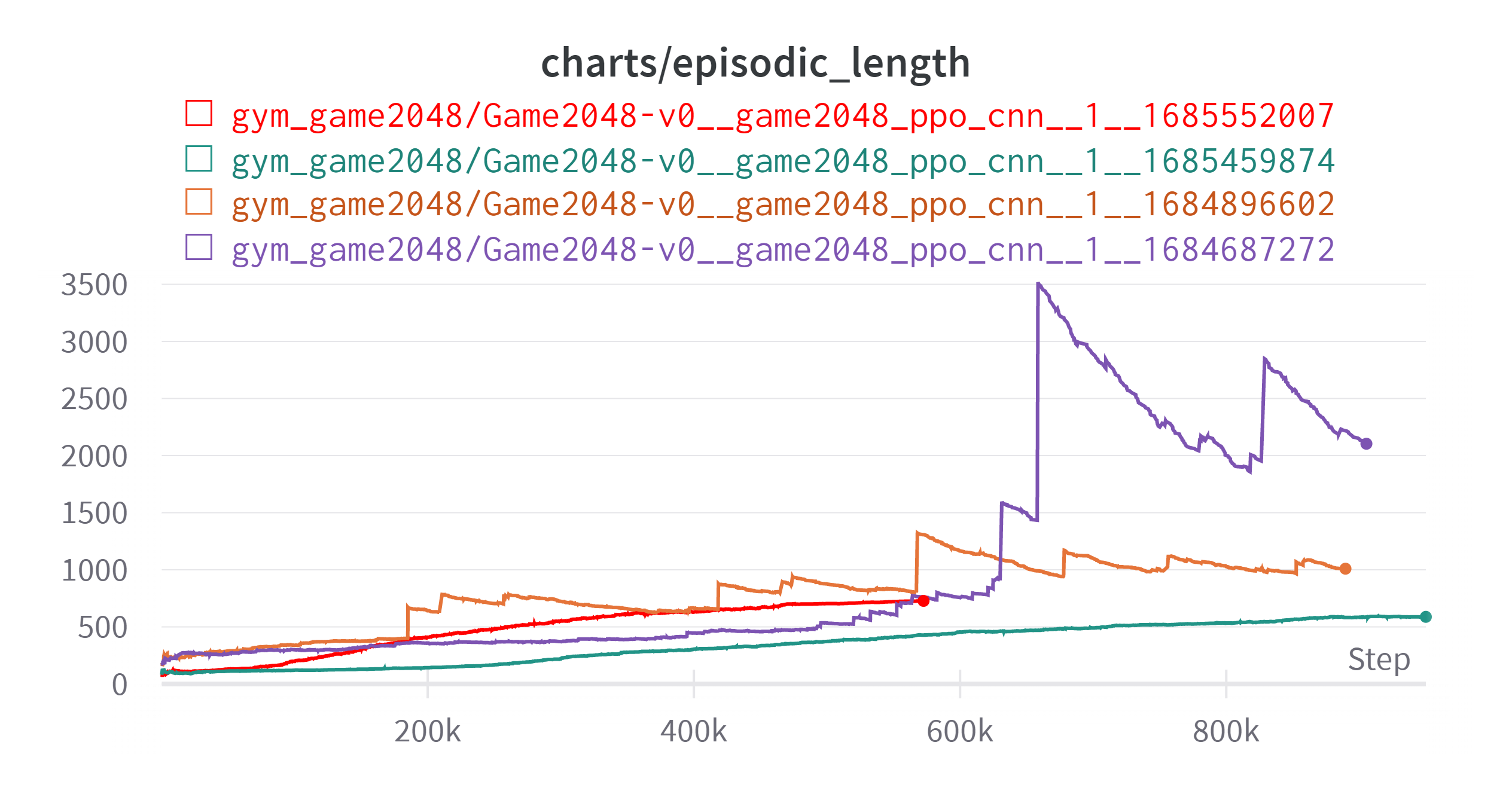
에피소드길이도 상당히 안정적인 것을 볼 수 있다.
마지막 100, 300개의 에피소드에서 66.6%의 클리어률을 보였다.
저장해둔 weight를 통해 100%에 최대한 수렴시켜보고 마무리할 생각이다.
★★13. 후에 Illegal Action을 적용하면서 게임 로직을 개선하였고 그 과정에서 중대한 버그가 있었다. “14. 개선된 결과” 내용은 잘못된 환경에서 실험된 결과이므로 완전히 잘못된 결과, 실험이다. 하지만 필자의 반성을 위해 남겨둔다.★★
(2023-06-07 10:11:29)
15. IllegalTerminate
Illegal Action에 대해 바로 Terminate를 적용하였다. 잘못된 환경이었던 14번과는 달리 실험은 훨씬 오래걸렸다.
결론적으로는 실험은 성공했다. 일단 차트를 먼저 올리고 내용을 설명해보겠다. 클리어률은 약 50%이다.
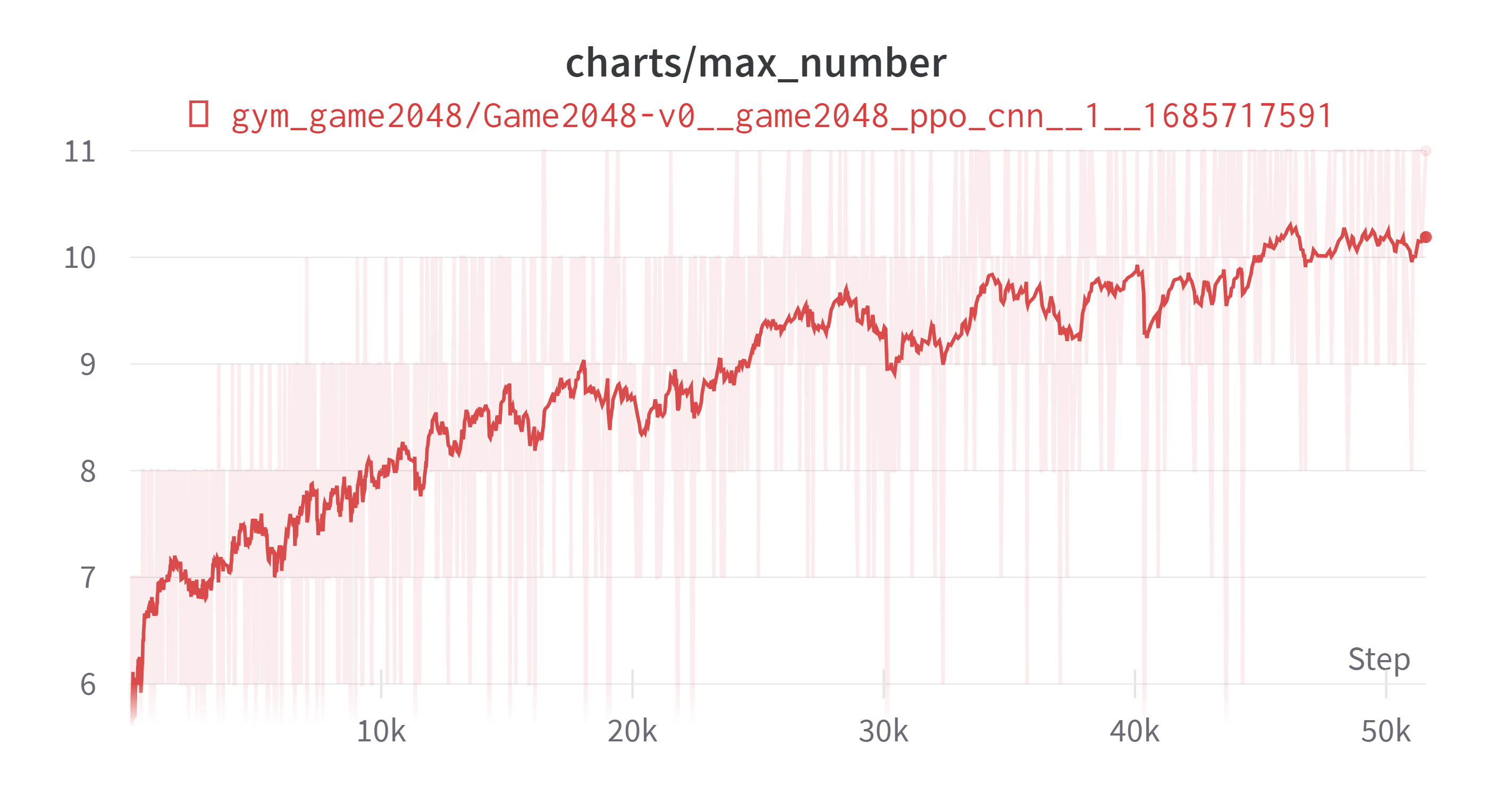
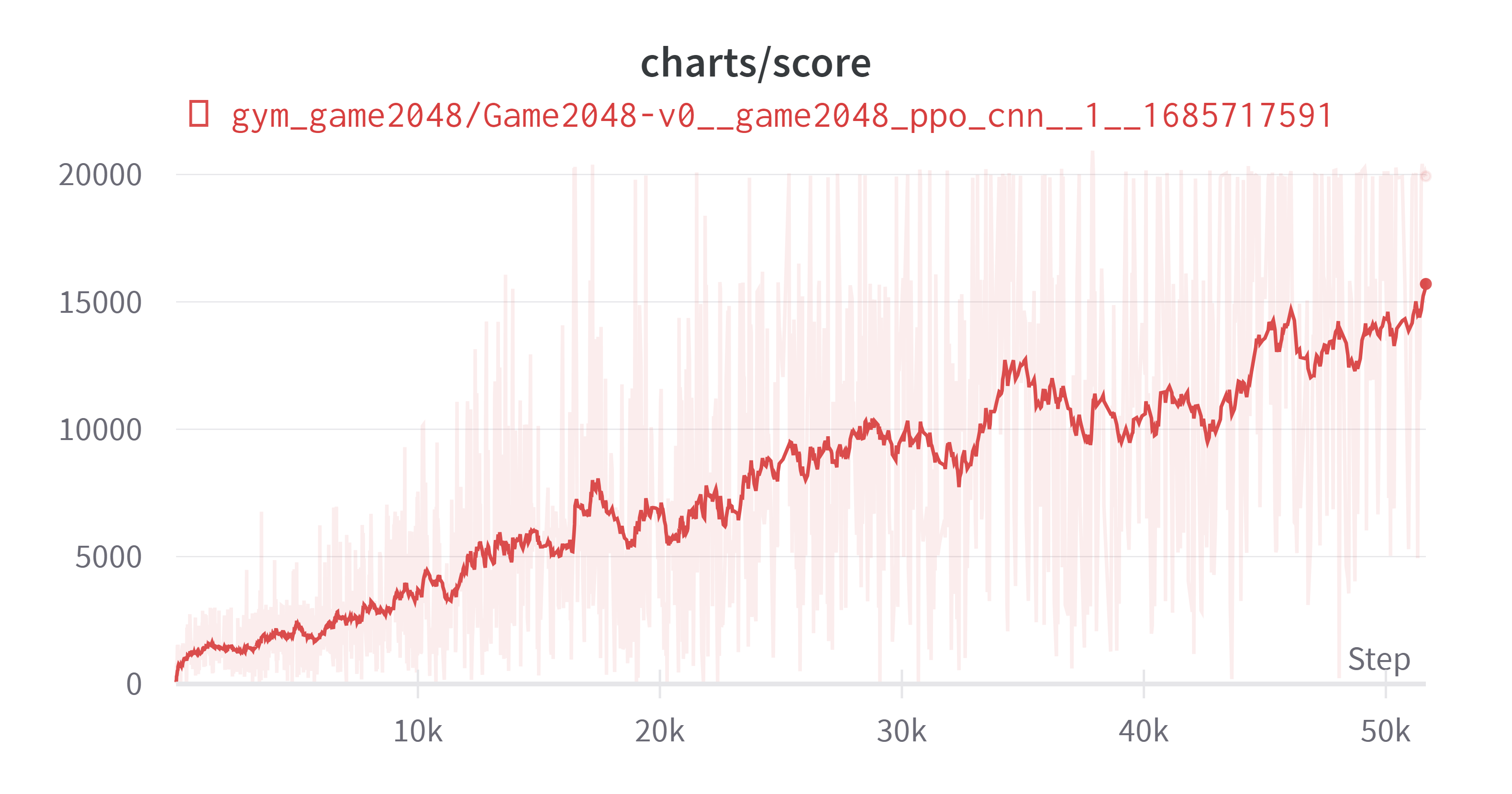
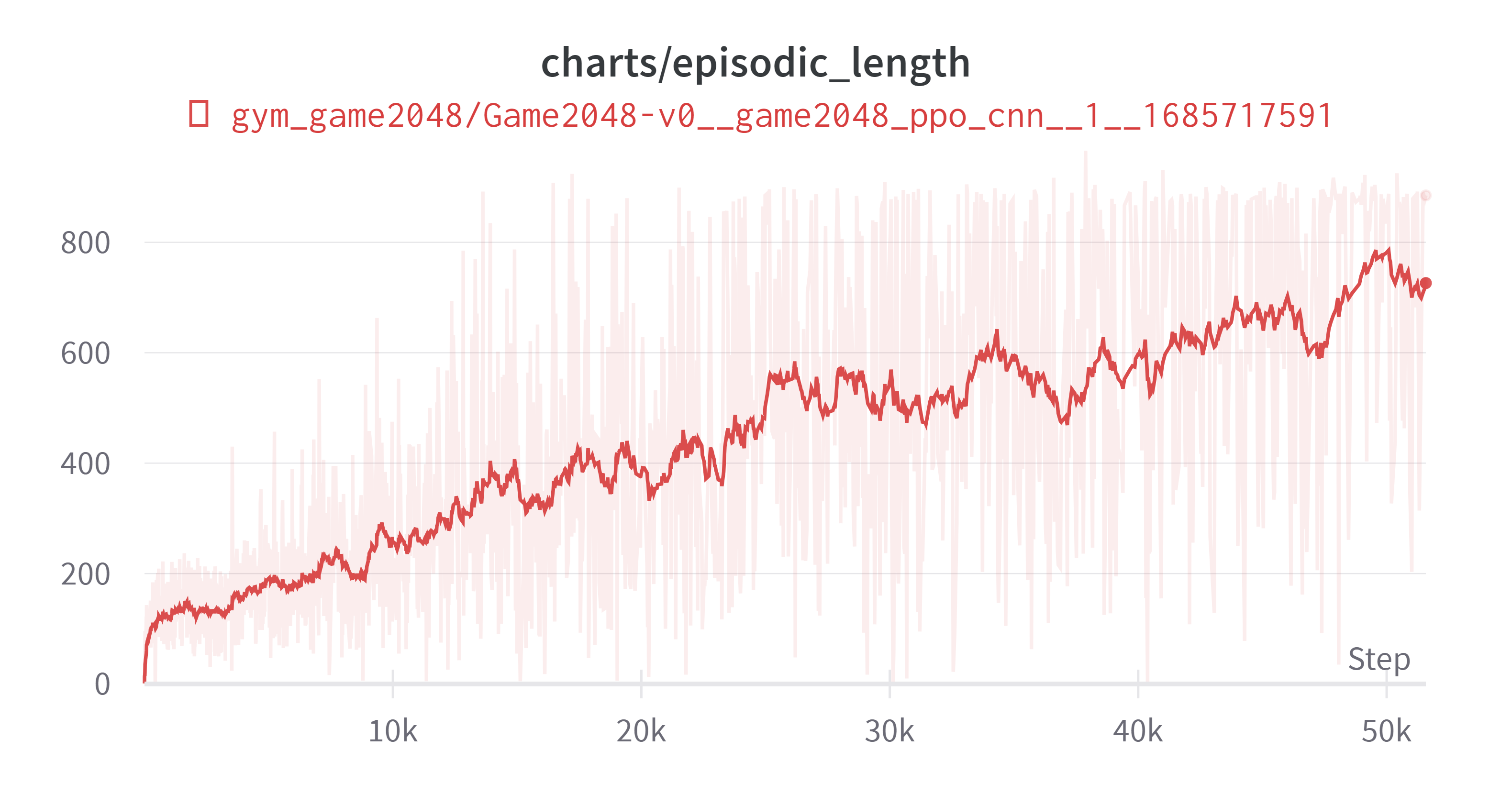
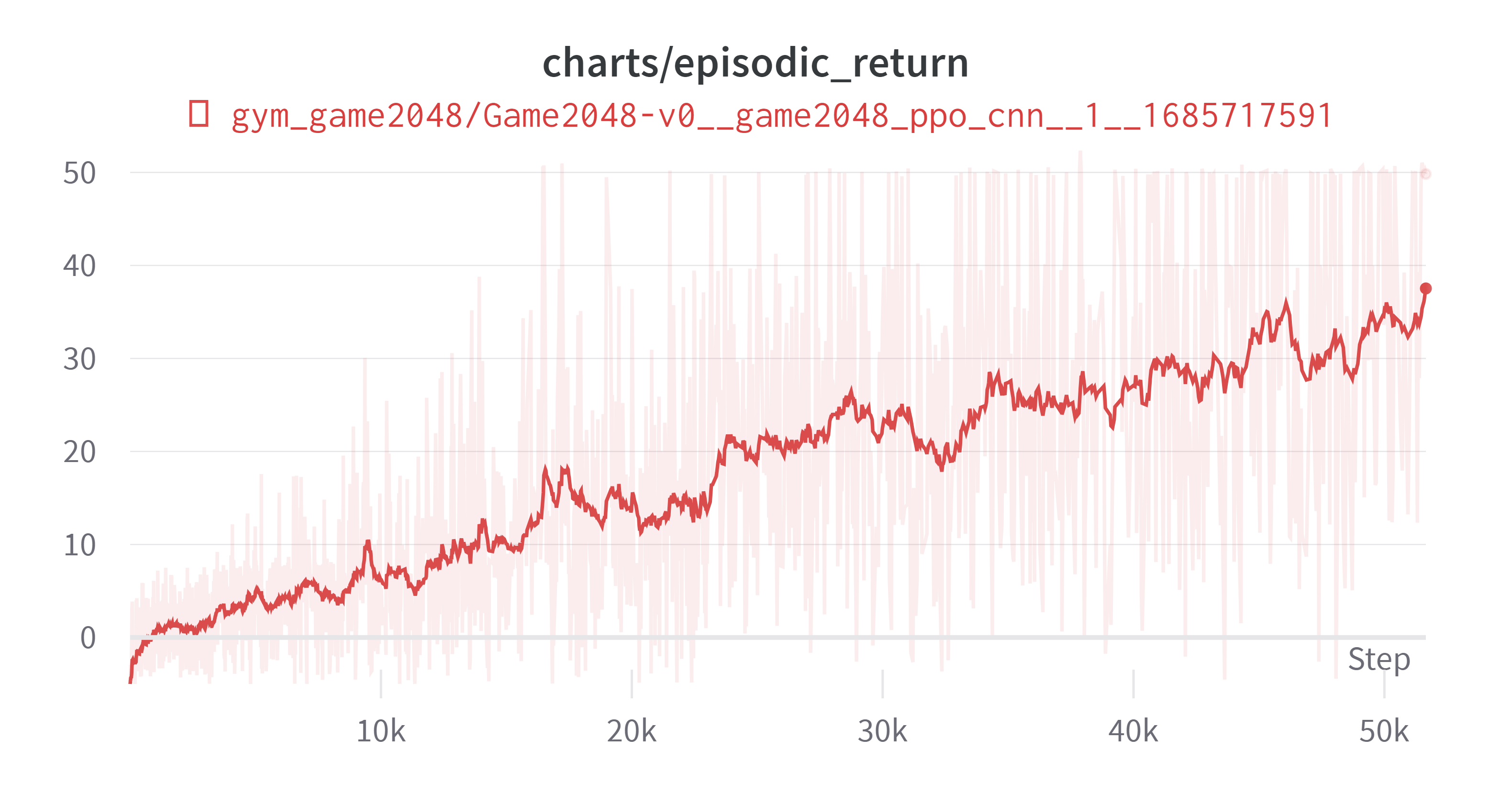
더 진행하면 더욱 개선될 것 같긴 하나 충분히 성공률도 높고 시간상의 제약으로 인하여 학습을 멈추었다. 학습시간은 i5-9500K, GTX 1660ti, RAM 16GB 기준으로 90시간 정도 소요되었다. 나머지 하이퍼파라미터는 마지막에 제시하고 다른 이야기를 먼저 적어보겠다.
가장 큰 변화는 IllegalTerminate (Illegal Action시에 바로 에피소드를 종료함)이다. 학습이 오래걸릴 것이라 생각했긴 했지만 이정도로 오래 걸릴 줄은 몰랐다.
이전 실험에서는 Illegal Action시에 에피소드를 유지했는데 바로 종료하는 것이 학습이나 나중에 활용시에 더 적합하다 생각이 들어 실험을 진행하였다.
바로 종료하는 것은 큰 단점인데 극단적인 예를 제시해 보겠다.
1
2
3
4
2 2 0 0
0 0 0 0
0 0 0 0
0 0 0 0
과 같은 상황으로 게임이 시작했다고 하자. 여기서 Illegal Action은 위로 올리는 행동이다. 그런데 에이전트가 이 행동을 선택했다면 게임을 바로 끝낸다. 이것이 시작할때 뿐만 아니라 Illegal Action이 가능한 상황이라면 언제든지 발생할 수 있는 것이다. 그래서 게임 진행 중간에 툭 죽어버리는 상황이 자주 발생하였다. 그러다가 나중에는 그런 행동을 회피하는 쪽으로 학습하였다.
보상 정책은 다음과 같다.
| 색 | 블록 합칠 때 | Illegal Action | Clear | 범위 |
|---|---|---|---|---|
| 빨강 | × 0.0025 | -5 | 0 | [-5, 5.12] |
클리어 상황에 대해 대해서는 보상을 주지 않았다. 나중에 4096같은 숫자로 확장 가능성도 있기도 하고 스코어를 높이는 것이 곧 클리어일 수 밖에 없다는 생각이 들었다. 1024 두개가 생기면 바로 합쳤을 때 점수가 약 2만점이 나오는데 두개를 합치지 않고 2만점을 만드는 것이 너무 힘들다. 에이전트는 큰 수일수록 구석으로 몰아가는데 1024 두개를 합치지 않은 채로 2만점을 넘기는 것은 거의 불가능한 일이기 때문이다.
전략은 거의 비슷하다. 한쪽 구석으로 큰 수를 몰아넣으면서 어쩔 수 없이 다른 수가 그 자리에 들어갔을 경우 큰 수 방향을 채우고 빼낸다. 그림으로보면 다음과 같다.

왼쪽같은 상황이 나왔다면 게임을 진행하면서 오른쪽 그림과 같이 큰 수 옆(왼쪽)에는 합칠 것이 없고 구석은 블록을 합칠 수 있거나, 빈 공간이 있는 것과 같이 왼쪽으로 움직여서 공간을 비울 수 있는 경우 옮겨서 큰 수를 위로 옮긴다.
(이는 꼭 위 그림과 같은 상황이 아니더라도, 보드를 회전하거나 뒤집어도 같은 원리로 적용된다.)
그리고 전체적인 전략은 다음과 같다.
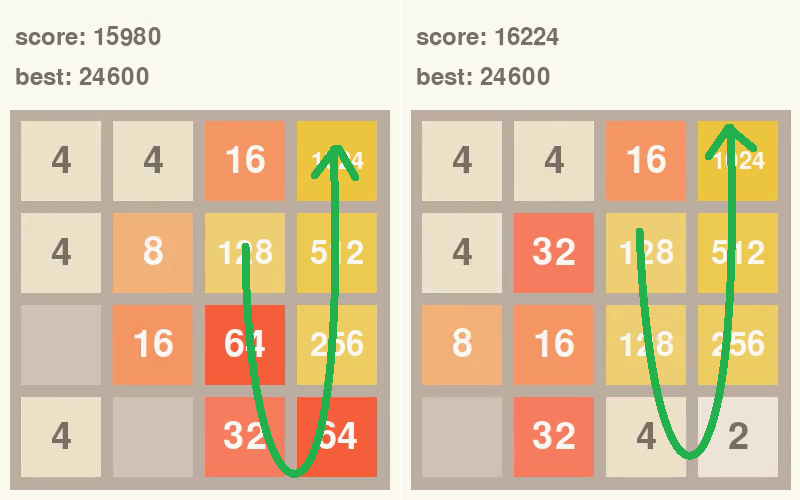
위와 같이 블록을 오름차순으로 구성하여 마지막에 합쳐서 게임을 끝내는 것이다. 위 그림을 기준으로 위로 올라갈수록, 오른쪽으로 갈 수록 숫자가 커진다.
아래는 플레이 영상이다.
학습 진행을 위한 하이퍼 파라미터는 다음과 같다.
| Name | ppo_cnn |
|---|---|
| anneal_lr | TRUE |
| batch_size | 2048 |
| clip_coef | 0.2 |
| clip_vloss | TRUE |
| cnn_channel | 128 |
| cuda | TRUE |
| ent_coef | 0.01 |
| gae_lambda | 0.95 |
| gamma | 0.99 |
| goal | 2048 |
| learning_rate | 0.00025 |
| linear_size | 512 |
| max_grad_norm | 0.5 |
| minibatch_size | 512 |
| norm_adv | TRUE |
| num_envs | 16 |
| num_minibatches | 4 |
| num_steps | 128 |
| seed | 1 |
| torch_deterministic | TRUE |
| total_timesteps | 1000000000 |
| track | TRUE |
| update_epochs | 4 |
| vf_coef | 0.5 |
| illegal_terminate | -5 |
16. 추가 연구
큰 틀에서 이 프로젝트를 마무리 할 생각이다. 아쉬운 점은 몇 개 있다.
- 성공률 100%가 가능한지 여부
- 다른 알고리즘과 비교
- 다른 시드에서 재현 여부
- 알고리즘 파라미터에 대한 이해
자원이 한정적이라 지금은 못하지만 추후에 계속 학습시켜보면서 성공률을 어느정도까지 끌어올릴 수 있는지, 다른 알고리즘과 비교, 다른 시드에서 재현 여부를 실험해볼 생각이다. 아마 시간이 남으면 실험 후에 이 페이지에 더 업로드할 것 같다.
17. action masking 적용
마무리하지 않고 더 해보았다.
관련 내용은 아래 서술하였다.
https://helpingstar.github.io/rl/invalid_action_masking/
이제 2048이 아니라 4096, 8192까지 도전해볼 생각이다.
18. 높은 성능과 보상설정
내 전체적인 보상 설정 방법은 점수 산정 방식과 같으며 스케일이 너무 크면 학습이 힘들어지기 때문에 그것을 어떤 수로 나누어 스케일하였다. 여기서는 512라고 하겠다. 예를 들어 512 블록 2개와 256 블록 두개를 합쳐서 블록 512, 1024 블록을 만들었다면 1536=512+1024 점수를 얻을 것이고 보상 책정시에는 그것을 512로 나누면 보상은 3을 얻을 것이다.
초기에는 2048이 최대 숫자라고 생각하고 (목표이기도 했고) 이것에 맞춰서 최고 보상값이 4 (5 이하) 가 되도록 512로 나눴다.

적당히 좋은 에이전트의 로그자료인데 에피소드가 종료될 때 보드에 있는 가장 좋은 숫자를 나타낸 것이다. $2^{13}$도 심심치않게 볼 수 있다. 이론상 만들 수 있는 최대 숫자는 $2^{17}$이다. 물론 매우 만들기 힘든 숫자지만 각 보상을 512로 나눠 스케일하는게 맞을까 하는 생각이 들었다.
그래서 보상을 2048=$2^{11}$로 나누기로 하였다. 이렇게 하고 이전 실험과 결과를 비교해보기로 하였다.