단단한 강화학습 코드 정리, chap9
단단한 강화학습 책의 코드를 공부하기 위해 쓰여진 글이다.
compute_true_value
전체적인 코드의 진행은 chap 4에 서술된 $V \approx v_{\pi}$를 위한 반복 정책 평가와 같다.

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
def compute_true_value():
# true state value, just a promising guess
true_value = np.arange(-1001, 1003, 2) / 1001.0
# Dynamic programming to find the true state values, based on the promising guess above
# Assume all rewards are 0, given that we have already given value -1 and 1 to terminal states
while True:
old_value = np.copy(true_value)
for state in STATES:
true_value[state] = 0
for action in ACTIONS:
for step in range(1, STEP_RANGE + 1):
step *= action
next_state = state + step
next_state = max(min(next_state, N_STATES + 1), 0)
# asynchronous update for faster convergence
true_value[state] += 1.0 / (2 * STEP_RANGE) * true_value[next_state]
error = np.sum(np.abs(old_value - true_value))
if error < 1e-2:
break
# correct the state value for terminal states to 0
true_value[0] = true_value[-1] = 0
return true_value
- (1) : 상태결집과 실제 값을 비교하는데 쓰이는 실제 값이다.
- (2~3) : 실제 값을 저장할 배열에 유망한 값들을 미리 저장한다. 1002개의 값이 저장되어 있으며 (-1001, …, 1001)으로 저장된 값들을 1001.0으로 나누기 때문에 (-1, …, 1) 이 저장된다.
- (5~6) : 유망한 값을 저장한 true_value를 기반으로 DP를 이용하여 실제 값을 찾아낸다. 마지막 state에서 1 또는 -1을 보상으로 받으며 나머지 상태에서는 보상이 0이다
- (7) : 종료 조건인 (19~20)에 해당할 때까지 반복한다.
- (8) : 이전의 추정치를 깊은 복사를 통해
old_value에 저장한다. $v \leftarrow V(s)$와 같다. 코드에서는 모든 상태에 대해 한번에 하므로 반복문 밖에서 진행한다. - (9) :
STATES = np.arange(1, N_STATES + 1)으로 $[1, 1000]$ 범위의 모든 상태에 대해서 계산을 진행한다. - (10) : 업데이트 하기 위한 현재 상태의
true_value를 0으로 초기화한다. - (11) : 왼쪽으로 갈 지 오른쪽으로 갈 지를 선택한다.
- (12) : 스텝의 범위에 대해 탐색한다.
STEP_RANGE = 100이기 때문에 $[1, 100]$ 범위에 대해서 탐색한다. - (13) : 스텝(크기)에 action(방향)을 곱하여 어떤 방향으로 어느정도 갈지를 정한다.
- (14) : 현재 상태에서 스텝만큼 움직이고 이를
next_state에 대입한다. - (15) : 0보다 작을경우 0으로,
N_STATES + 1(1001) 보다 클 경우N_STATES + 1로 클리핑한다. - (16) : 비동기 동적 프로그래밍을 사용하여 업데이트 한다면 더 빨리 수렴될 것이라는 것이다 자세한 내용은 책의 4.5단원을 참고하면 된다
- (17) :
이 공식은 DP의 반복 정책평가의 공식과 같은데 천천히 설명해보겠다. 일단 정책평가의 공식은 다음과 같다.
\[V(s) \leftarrow \sum_{a} \pi(a \vert s) \sum_{s',r}p(s',r \vert s,a) \left [ r + \gamma V(s') \right ] \tag{17.2}\]여기서 2는 방향의 개수를 의미하고 step_range는 스텝의 개수를 의미한다. 그리고 모든 행동은 동일한 확률로 추출되므로 다음과 같다.
\[\frac{1}{2 * \text{(step range)}} = \pi(a \vert s)\]또한 deterministic 한 환경이므로 전이확률은 1이다.
\[p(s', r \vert s, a) = 1\]그리고 terminal_state를 제외하고 $r=0$이고 $\gamma=1$이다. 또한 (11~12) 부분에서 for문을 통해 값을 누적한 것은 $\sum$을 표현한 것이라 할 수 있다.
그러므로 $(17.1)$은 코드의 예시에 맞춰 $(17.2)$를 표현한 것이라 볼 수 있다.
- (18) : 이전 값인
old_value와 이를 기반으로 새롭게 산출한true_value의 절댓값 차이를 모두 더하여error에 대입한다. $\Delta \leftarrow \max ( \Delta, \vert v - V(s) \vert)$에 대응하는 부분이라고 할 수 있다. 반복의 종료 조건을 설정하는 것인데 알고리즘에서는 값 차이(error)의 최대값으로 하였다. - (19~20) : 절댓값의 차이의 합이 0.01보다 작을 때까지 반복한다. $\text{until } \Delta < \theta$ 에 대응하는 부분이다.
- (21~22) : terminal state에 대해 가치를 0으로 만든다. // TODO
- (24) : true_value 테이블을 반환한다.
step
1
2
3
4
5
6
7
8
9
10
11
12
13
# take an @action at @state, return new state and reward for this transition
def step(state, action):
step = np.random.randint(1, STEP_RANGE + 1)
step *= action
state += step
state = max(min(state, N_STATES + 1), 0)
if state == 0:
reward = -1
elif state == N_STATES + 1:
reward = 1
else:
reward = 0
return state, reward
- (3) : $[1, \text{STEP_RANGE}]$ 범위에서 한 정수를 무작위로 추출하여
step에 대입한다. - (4) : 해당
step에action을 곱한다 (action은 (-1 / 1)로 (왼쪽 / 오른쪽)을 의미한다.) - (5) : 현재
state에step을 더하여state를 옮긴다. - (6) :
state가 0보다 작을 경우 0으로N_STATES+1보다 클 경우N_STATES+1로 클리핑한다. - (7~12) :
state가 0(왼쪽 끝)일 경우 -1,N_STATES+1 일 경우 1, 그 외는 0를reward로 받는다. - (13) :
state(새로운 상태),reward를반환한다.
get_action()
1
2
3
4
5
# get an action, following random policy
def get_action():
if np.random.binomial(1, 0.5) == 1:
return 1
return -1
- (3) :
numpy.random.binomial(n, p, size=None) : Draw samples from a binomial distribution.
p의 당첨확률을 가진 복권을 n개 사서 몇개가 당첨될지 테스트를 size번 하는 것이다.
이항분포 확률에 따라 0에서 n까지의 숫자중 하나를 출력한다. 0부터 n까지의 숫자 중 어떤 숫자 x(p에 몇번 해당되었는지)가 산출될 확률은 아래와 같다.
\[P(x)=\binom{n}{x}p^x(1-p)^{n-x}\]$n$ : number of trial, $p$ probability of success, $x$: number of successes.
코드에서는 np.random.binomial(1, 0.5)으로 되어 있는데 그러면 반환값이 1이 나올 확률이 0.5이 된다는 뜻이다. 그러므로 해당 조건문은 0.5의 확률로 True를 반환한다.
ValueFunction
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# a wrapper class for aggregation value function
class ValueFunction:
# @num_of_groups: # of aggregations
def __init__(self, num_of_groups):
self.num_of_groups = num_of_groups
self.group_size = N_STATES // num_of_groups
# thetas
self.params = np.zeros(num_of_groups)
# get the value of @state
def value(self, state):
if state in END_STATES:
return 0
group_index = (state - 1) // self.group_size
return self.params[group_index]
# update parameters
# @delta: step size * (target - old estimation)
# @state: state of current sample
def update(self, delta, state):
group_index = (state - 1) // self.group_size
self.params[group_index] += delta
- (5) :
self.num_of_groups: 결집의 개수(몇 개로 결집할 것인지), 10개 - (6) :
self.group_size: 한 결집에 포함된 상태의 개수 (N_STATES // num_of_groups== 100) - (8~9) : $\theta$, 각 state들을 결집해서 근사한 group의 value를 저장할 배열
- (11~12) : state의 value를 반환하는 함수이다.
- (13~14) : state가 0 또는
N_STATES+1 == 1001일 경우 0을 반환한다. - (15) : state를 해당하는 group으로 바꿔준다. {0: [1, 100], 2: [101, 200], …, 9: [901, 1000]} 과 같이 10개로 나눠진다.
- (16) : 해당하는
group_index의 value를 반환한다. - (18~21) : delta와 현재 state를 받아서 value를 업데이트하는 함수
- (22) : group_index를 구한다. (15) 와 같다.
- (23) : \(\textbf{w} \leftarrow \textbf{w} + \alpha \left [ G_t-\hat{v}(S_t, \textbf{w}) \right ]\nabla \hat{v}(S_t, \textbf{w})\)
gradient_monte_carlo

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# gradient Monte Carlo algorithm
# @value_function: an instance of class ValueFunction
# @alpha: step size
# @distribution: array to store the distribution statistics
def gradient_monte_carlo(value_function, alpha, distribution=None):
state = START_STATE
trajectory = [state]
# We assume gamma = 1, so return is just the same as the latest reward
reward = 0.0
while state not in END_STATES:
action = get_action()
next_state, reward = step(state, action)
trajectory.append(next_state)
state = next_state
# Gradient update for each state in this trajectory
for state in trajectory[:-1]:
delta = alpha * (reward - value_function.value(state))
value_function.update(delta, state)
if distribution is not None:
distribution[state] += 1
- (6) : 현재 상태
state를START_STATE== 500 으로 둔다 - (7) : trajectory를 추적할 리스트의 초깃값으로
state를 넣는다. - (9) : termination에서 1 혹은 -1의 보상을 얻고 이외의 상태에서는 0의 보상을 얻으므로 $\gamma=1$이면 return이 마지막의 보상과 같다.
- (11) : state가
END_STATES = [0, N_STATES + 1]에 포함되지 않을 때까지 (양 끝에 도달하기 전까지) 반복문을 실행한다. - (12) : 행동 둘 중 하나를 0.5의 확률로 정한다.
- (13) :
step함수에 현재 상태(state)와 행동(action)을 인수로 집어넣어 다음 상태(next_state)와 보상(reward)를 받는다. - (14) : (7)에서 정의한
trajectory에 (13)에서 얻은 새로운 상태(next_state)를 append한다. -
(15) : 새로운 상태를 state에 저장한다.
- (17) : trajectory의 각 state에 대해 gradient update를 한다.
- (18) : 마지막 state를 제외하고 state를 처음부터 탐색한다.
- (19) : $\text{delta}=\alpha \left [ G_t-\hat{v}(S_t, \textbf{w}) \right ]$, 환경 특성상 $G_t = R_T$ 이다
- (20) : 구한 delta와 탐색하는 state에 대해 업데이트 한다.
- (21~22) :
distribution이 주어질 경우 방문한 state 인덱스의 값을 1 늘린다.
semi_gradient_temporal_difference

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
# semi-gradient n-step TD algorithm
# @valueFunction: an instance of class ValueFunction
# @n: # of steps
# @alpha: step size
def semi_gradient_temporal_difference(value_function, n, alpha):
# initial starting state
state = START_STATE
# arrays to store states and rewards for an episode
# space isn't a major consideration, so I didn't use the mod trick
states = [state]
rewards = [0]
# track the time
time = 0
# the length of this episode
T = float('inf')
while True:
# go to next time step
time += 1
if time < T:
# choose an action randomly
action = get_action()
next_state, reward = step(state, action)
# store new state and new reward
states.append(next_state)
rewards.append(reward)
if next_state in END_STATES:
T = time
# get the time of the state to update
update_time = time - n
if update_time >= 0:
returns = 0.0
# calculate corresponding rewards
for t in range(update_time + 1, min(T, update_time + n) + 1):
returns += rewards[t]
# add state value to the return
if update_time + n <= T:
returns += value_function.value(states[update_time + n])
state_to_update = states[update_time]
# update the value function
if not state_to_update in END_STATES:
delta = alpha * (returns - value_function.value(state_to_update))
value_function.update(delta, state_to_update)
if update_time == T - 1:
break
state = next_state
- (6~7) : 초기 state에 시작 상태를 대입한다.
START_STATE = 500 - (9~12) : state와 reward를 저장할 리스트를 생성한다. mod trick을 이용하면 state, reward를
n만큼만 생성해도 되지만, 편리한 구현을 위해 모두 저장한다. - (14~15) : termination까지 진행된 tiem step의 개수를 저장한다.
- (17~18) : 마지막 time step을 의미하는 $T$를 $\infty$로 초기화한다.
- (23~24) : 에피소드의 길이를 저장한다.
- (20~21) : 타임스텝이 진행됨으로써
time에 1을 더한다. - (23) : 1씩 증가하는
time이 $T$보다 작으면 진행한다. (32~33) 에서END_STATES로 가면서 $T$에time이 대입되면 이 조건문은 실행되지 않는다. - (24~25) : get_action() 함수를 이용하여 왼쪽, 오른쪽 중 하나를 50% 확률로 선택한다.
- (26) : step(state, action) 함수에 따라 $s_t, a_t$ 를 인수로 주고 $s_{t+1}, r_{t+1}$를 얻는다.
- (28~30) : $s_{t+1}, r_{t+1}$를 리스트에 저장한다.
- (32~33) : 만약 $s_{t+1}$이
END_STATES = [0, N_STATES + 1]에 속한다면 마지막 time step을 의미하는 $T$에 현재time을 대입한다. - (35~36) : $\tau \leftarrow t - n + 1$인데 코드는
update_time = time - n인 이유 : 코드상에서는 구현상 (21)에서 1을 더한다. 책에서는 $R_{t+1}, S_{t+1}$를 구할 때 $t$인데 코드에서는 $t+1$이다. 그러므로 코드상에서는 1이 미리 더해져 있으므로 n만 빼는 것이다. - (37) : 업데이트를 시작하는
update_time이 0 이상인지 확인한다. - (38) : return 값인 $G$ 를 저장할
returns변수를 선언한다. - (39~41) :
현재 환경에서는 $\gamma = 1$이므로 해당 부분을 생략한다. 만약 $\gamma \neq 1$ 이라면 returns += pow(GAMMA, t-update_time-1) * rewards[t] 가 되었을 것이다.
- (42~44) : $\hat{v}(\text{terminal}, \cdot)=0$ 이므로 terminal이 아닐 경우 ($\text{If } \tau + n < T$)
- (45) : 업데이트하고자 하는 state를
start_to_update에 저장한다 ($S_{\tau}$와 같다) - (46~49) : 만약 $S_{\tau}$가 terminal state가 아니라면 ($\tau \neq T$) 다음과 같이 업데이트를 진행한다.
여기서 $\text{delta} = G - \hat{v}(S_{\tau}, \textbf{w})$이다 이것을 value_function.update()를 이용해 $\textbf{w}$를 조정한다.
- (50~51) : $\tau = T - 1$ 이 되면 반복문을 종료한다.
- (52) : state를 갱신한다.
BasesValueFunction
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
# a wrapper class for polynomial / Fourier -based value function
POLYNOMIAL_BASES = 0
FOURIER_BASES = 1
class BasesValueFunction:
# @order: # of bases, each function also has one more constant parameter (called bias in machine learning)
# @type: polynomial bases or Fourier bases
def __init__(self, order, type):
self.order = order
self.weights = np.zeros(order + 1)
# set up bases function
self.bases = []
if type == POLYNOMIAL_BASES:
for i in range(0, order + 1):
self.bases.append(lambda s, i=i: pow(s, i))
elif type == FOURIER_BASES:
for i in range(0, order + 1):
self.bases.append(lambda s, i=i: np.cos(i * np.pi * s))
# get the value of @state
def value(self, state):
# map the state space into [0, 1]
state /= float(N_STATES)
# get the feature vector
feature = np.asarray([func(state) for func in self.bases])
return np.dot(self.weights, feature)
def update(self, delta, state):
# map the state space into [0, 1]
state /= float(N_STATES)
# get derivative value
derivative_value = np.asarray([func(state) for func in self.bases])
self.weights += delta * derivative_value
- (1) : 다항식/푸리에 기저 가치함수를 위한 클래스
- (2~3) : 기저를 구분하기 위해 변수로
POLYNOMIAL_BASES = 0; FOURIER_BASES = 1를 저장한다. - (4) : 클래스 선언
- (5~7) : 생성자를 선언한다
order: 기저의 수, 각 함수에는 상수 매개변수가 하나 더 있다(머신 러닝에서는 편향이라고 함).type: 다항식 기저 / 푸리에 기저
- (9) : // TODO
- (11~12) : 기저 함수를 저장한다
self.bases에는 각 기저함수가 저장된다. - (13~15) : 다항식 기저일 경우 아래 식을 계산하는 함수를
self.bases에 추가한다.
- (16~18) : 푸리에 기저일 경우 아래 식을 계산하는 함수를
self.bases에 추가한다.
figure 9_1
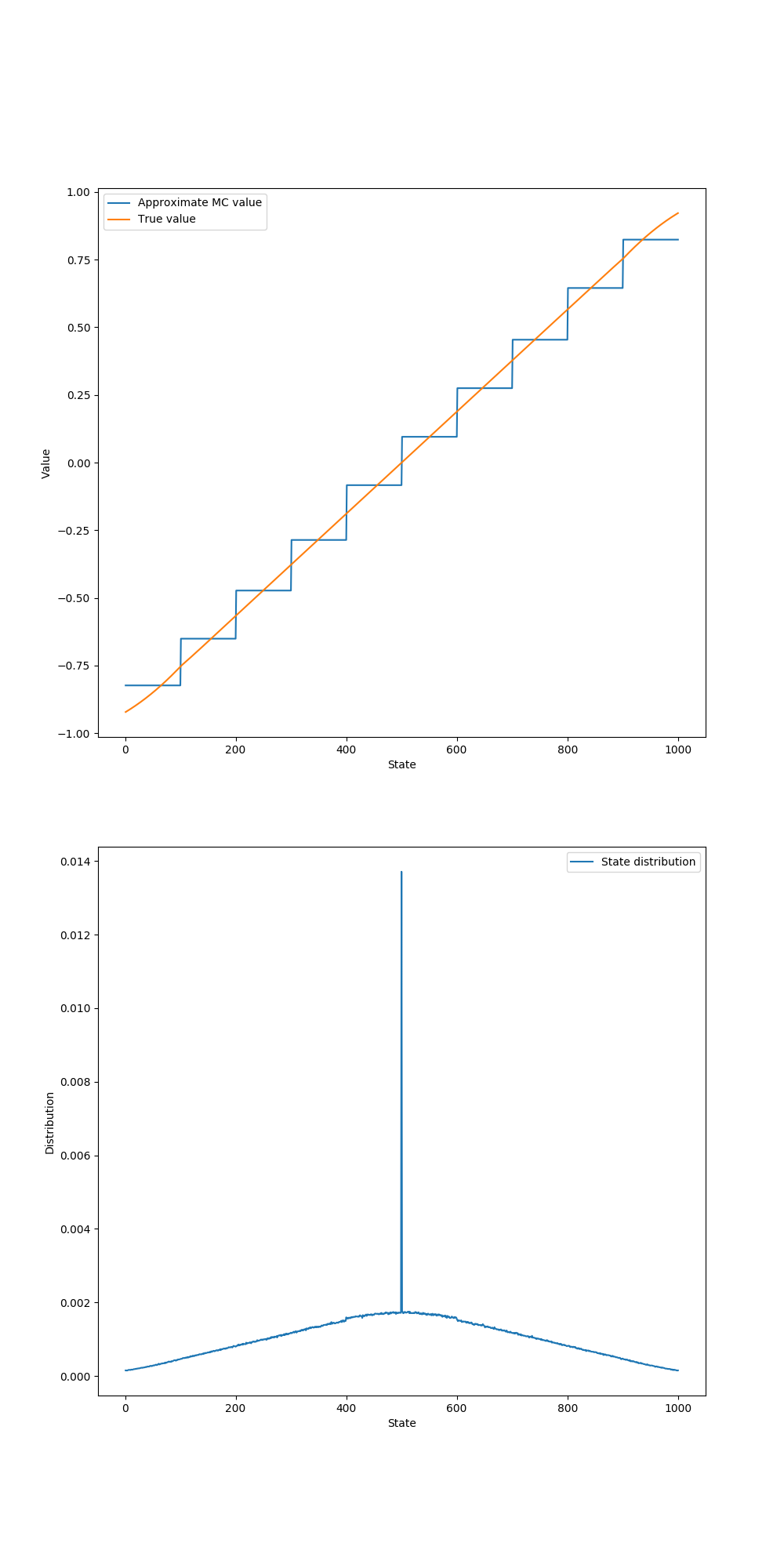
1
2
3
4
5
6
7
8
9
10
11
12
13
# Figure 9.1, gradient Monte Carlo algorithm
def figure_9_1(true_value):
episodes = int(1e5)
alpha = 2e-5
# we have 10 aggregations in this example, each has 100 states
value_function = ValueFunction(10)
distribution = np.zeros(N_STATES + 2)
for ep in tqdm(range(episodes)):
gradient_monte_carlo(value_function, alpha, distribution)
distribution /= np.sum(distribution)
state_values = [value_function.value(i) for i in STATES]
- (4) :
alpha: step size - (7) : 10개로 결집된 상태의 가치를 나타내는 클래스를 정의한다.
- (8) : 전체 상태의 방문 횟수를 계산한다.
- (9~10) :
episodes횟수만큼gradient_monte_carlo를 수행한다. - (12) :
- (13) : 각 state의 가치를 저장한다.
N_STATES = 1000STATES = np.arange(1, N_STATES + 1)
figure 9_2
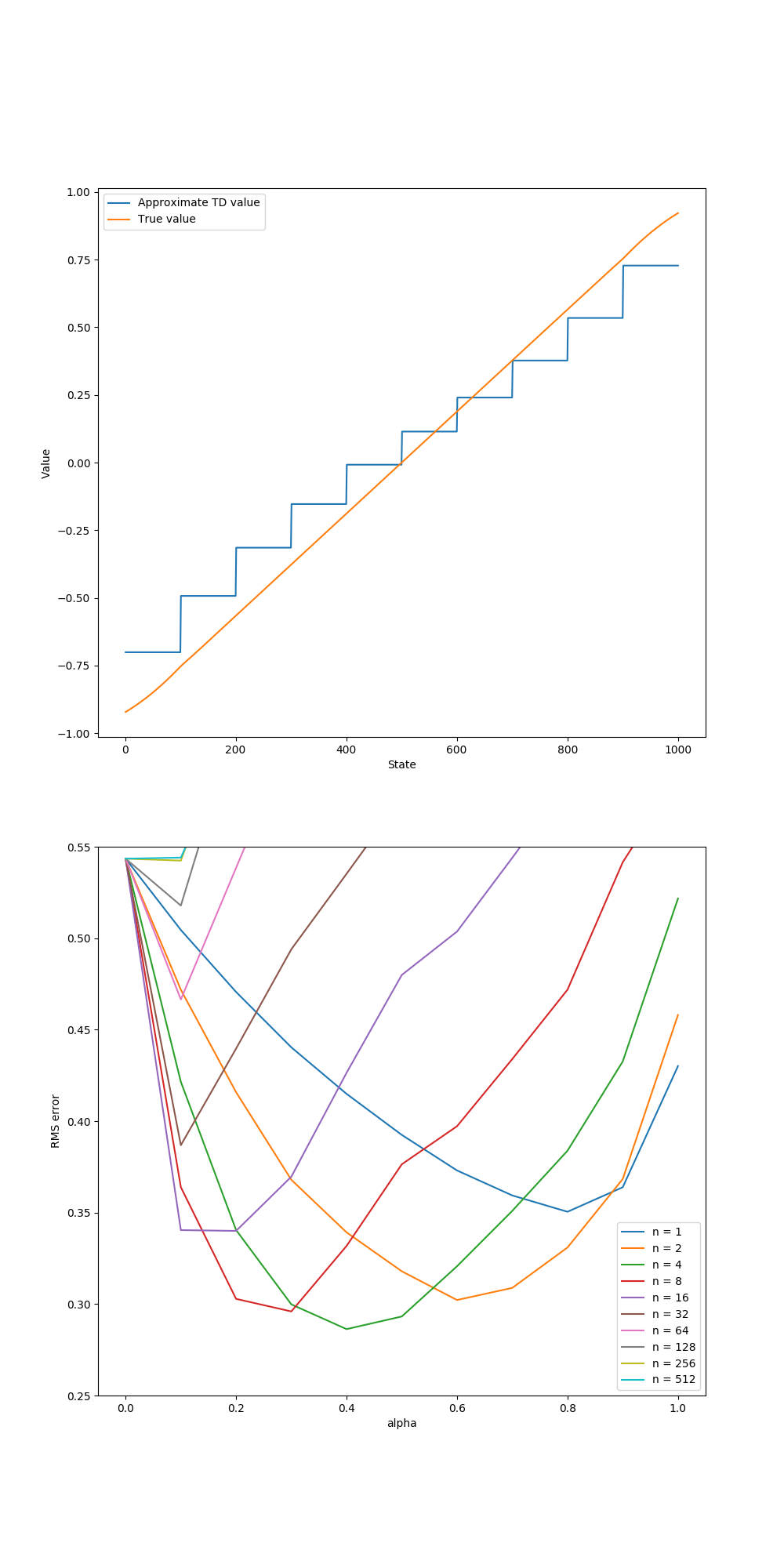
figure 9_2 left
1
2
3
4
5
6
7
8
9
# semi-gradient TD on 1000-state random walk
def figure_9_2_left(true_value):
episodes = int(1e5)
alpha = 2e-4
value_function = ValueFunction(10)
for ep in tqdm(range(episodes)):
semi_gradient_temporal_difference(value_function, 1, alpha)
stateValues = [value_function.value(i) for i in STATES]
figure 9_2 right
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# different alphas and steps for semi-gradient TD
def figure_9_2_right(true_value):
# all possible steps
steps = np.power(2, np.arange(0, 10))
# all possible alphas
alphas = np.arange(0, 1.1, 0.1)
# each run has 10 episodes
episodes = 10
# perform 100 independent runs
runs = 100
# track the errors for each (step, alpha) combination
errors = np.zeros((len(steps), len(alphas)))
for run in tqdm(range(runs)):
for step_ind, step in zip(range(len(steps)), steps):
for alpha_ind, alpha in zip(range(len(alphas)), alphas):
# we have 20 aggregations in this example
value_function = ValueFunction(20)
for ep in range(0, episodes):
semi_gradient_temporal_difference(value_function, step, alpha)
# calculate the RMS error
state_value = np.asarray([value_function.value(i) for i in STATES])
errors[step_ind, alpha_ind] += np.sqrt(np.sum(np.power(state_value - true_value[1: -1], 2)) / N_STATES)
# take average
errors /= episodes * runs
- (1~2) : n-step, step size를 서로 다르게 하여 각각의 준경사도 TD의 성능을 측정하기 위한 함수이다.
- (3~4) : n-step의 리스트이며 $n \in \{ 2^0, 2^1, \cdots ,2^8, 2^9 \}$를 가진다.
- (6~7) : 가능한 step size, $\alpha \in \{0, 0.1, …, 0.9, 1.0 \}$
- (9~10) : 각각의 실행은 10번의 에피소드를 가진다
- (12~13) : 결과는 100개의 결과를 평균한다.
- (15~16) : 각 n-step, step size의 결과를 저장하는 행렬이다. 해당 예시는 (10, 10)이다
- (17) : 100번의 실행을 평균하기 위해 100번 반복한다.
- (18~19) : 각각의 n-step, $\alpha$ 에 대해 실험을 진행한다. 실험 결과를 해당하는 배열에 저장하기 위해 인덱스도 같이 포함한다,
zip으로 하기보다는enumerate를 쓰는 것이 더 깔끔하다. - (20~21) : 책에서 나온 바와 같이 한 묶음당 50개의 상태를 갖는 20개의 묶음으로 상태를 결집한다.
- (23) : 지정한 하이퍼파라미터로 n단계 준경사도 TD 연산을 실행하고 추정한 가치를
value_function에 저장한다. - (24) : $\hat{v}$의 RMS Error 를 계산한다.
- (25) : 모든 상태에 대해 $\hat{v}(s, \textbf{w})$를 리스트에 저장한다.
- (26) : $\text{Error}(n, \alpha) = \sqrt{\frac{1}{n}\sum_{s} (\hat{v}(s, \textbf{w}) - v(s))^2}$
- (27~28) : 누적한 Error에 대해 (에피소드 횟수) * (반복 횟수)로 나눠 평균을 얻는다.
figure 9_5
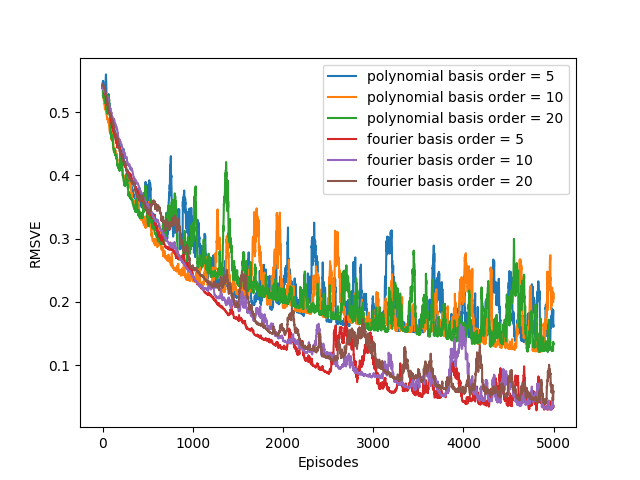
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# Figure 9.5, Fourier basis and polynomials
def figure_9_5(true_value):
# my machine can only afford 1 run
runs = 1
episodes = 5000
# # of bases
orders = [5, 10, 20]
alphas = [1e-4, 5e-5]
labels = [['polynomial basis'] * 3, ['fourier basis'] * 3]
# track errors for each episode
errors = np.zeros((len(alphas), len(orders), episodes))
for run in range(runs):
for i in range(len(orders)):
value_functions = [BasesValueFunction(orders[i], POLYNOMIAL_BASES), BasesValueFunction(orders[i], FOURIER_BASES)]
for j in range(len(value_functions)):
for episode in tqdm(range(episodes)):
# gradient Monte Carlo algorithm
gradient_monte_carlo(value_functions[j], alphas[j])
# get state values under current value function
state_values = [value_functions[j].value(state) for state in STATES]
# get the root-mean-squared error
errors[j, i, episode] += np.sqrt(np.mean(np.power(true_value[1: -1] - state_values, 2)))
# average over independent runs
errors /= runs
- (1~2) : 푸리에 기저와 다항식 기저를 비교한다.
- (3~4) : 실행을 몇번 할 것인지를 선택한다 (코드 저자의 경우 1번)
- (6) : 한 실험당 몇 번의 에피소드를 진행할 것인지 선택한다.
- (8~9) : // TODO BaseValueFunction