강화학습 코드/환경 구현시 팁
강화학습 알고리즘/논문 구현시 겪었던 고충들을 늘어놓고 해결할 때마다 업데이트 하기 위한 글이다. 지속적으로 업데이트 할 예정이다.
1.
state는 대부분 np.array인데 이것을 ReplayBuffer에 저장하기 위해서 list에 저장하면 torch.tensor로 옮길 때 옮겨지긴 하지만 Warning이 발생한다.
1
2
3
4
UserWarning:
Creating a tensor from a list of numpy. ndarrays is extremely slow.
Please consider converting the list to a single numpy.
ndarray with numpy.array() before converting to a tensor.
문제 자체의 원인과 해결 방법
torch.tensor([np.array, np.array])와 같이 리스트 안에 들어가 있는 np.array를 tensor로 바꾸면 오래걸리니 다차원 np.ndarray로 바꿔서 바꾸든 다른 방법을 이용하라는 것이다. 아마 주소할당이 복잡해서 내는 Warning인 듯 하다.
여러 해결 방법이 있다.
1
2
3
4
5
6
7
8
9
>>> import torch
>>> import numpy as np
>>> a = np.array([1, 2, 3])
>>> b = np.array([2, 3, 4])
>>> test = [a, b]
>>> test
[array([1, 2, 3]), array([2, 3, 4])]
>>> torch.tensor(test)
<stdin>:1: UserWarning: Creating a tensor from a list of numpy. ndarrays is extremely slow...
torch.tensor(np.array(test))- 리스트를
np.array로 감싸서 다차원np.ndarray를 만든다.
- 리스트를
torch.tensor(np.append(a, b).reshape(-1, 2, 3))- 즉석에서 만들어봤는데 효율적인 방법은 아닌 듯하다
핵심은 list안에 np.array를 넣고 그것을 torch.tensor로 변환하지 말라는 것이다
강화학습 구현 측면에서 해결 방법
그러면 2차원으로 단순히 하면되는 것 아닌가? 하겠지만 한 transition에는 (s, a, r, s', done)이 포함되기 때문에 단순히 state만 볼 수 없다.
->
내가 본 코드는 이 코드였다. 일단 가장 기본적인 해결 방법은 ReplayBuffert 수준에서 Tensor를 반환하지 않는 것이다. 해당 코드는 학습을 위해 최대한 코드를 줄이느라 그런 것 같다.
그래서 더 좋은 코드가 더 있을까 하고 stable_baselines3/common/buffers.py을 봤는데 다음과 같은 방법이 선호되는 듯 하다.
memory를 아끼고 싶다면 맨 처음에 빈 배열로 초기화 되고 memory가 꽉 찰 때까지 transition을 추가한다. 아니면 처음부터 최대 버퍼 크기만큼 공간을 확보하고 transition을 추가한다.
여기서 추가와 삭제는 pos(커서)와 모듈러(%) 연산으로 한다. 모듈러 연산을 통해 메모리를 순환하면서 FIFO로 transition을 append하거나 버퍼가 꽉차면 덮어쓴다.
2.
torch.tensor로 casting할 타이밍을 모르겠다. 어떤 구현에선는 ReplayBuffer에서 numpy를 input으로 받고 tensor를 반환한다. 하지만 어떤 구현에서는 numpy를 input으로 받고 똑같이 numpy를 반환한다. 어떤 것이 범용적인지 좀 더 공부와 구현을 해보고 판단해야겠다.
-> 생각보다 간단한 문제였던 것 같다. 너무 pytorch기준으로 생각해서 그랬던 것 같다. tensorflow를 쓸 수도 있고 pytorch를 쓸 수도 있으니 model에 넣기 직전에 적절한 tensor로 바꿔주는 것이 맞고 전처리나 기타 함수에서는 numpy를 받았다면 numpy를 반환하는 것이 맞다.
3.
강화학습 환경의 observation_space에 관한 고민이다. 보드게임 환경을 구현했는데 (9, 9) 보드에 블록을 놓으면 되는 게임이어서 (놓지 않음/ 놓음) 은 0과 1로 구별하면 된다. 그리고 블럭 3개도 포함해야 하기 때문에 observation_space를 MultiBinary([15, 15])로 하였다.
그런데 내가 공부가 부족해서 그런지 모르겠지만 고민이 많다. rank=3로해서 [15, 15, 1]로 해야 할지 위와 같이 rank를 2로 할지에 대한 것이다. 알고리즘상 CNN을 통과해야 하기 때문에 rank=3인 것이 좋다. 그런데 여기서 고민이 발생한다.
1) env.observation_space를 rank=3으로 설정하고
1) 메커니즘을 처음부터 rank=3으로 구현하는 지
2) 계산은 rank=2으로 하고 마지막 반환 직전에 rank=3으로 변환할지
2) env.observation_space를 rank=2으로 설정하고
1) 반환받은 observation을 rank=3으로 변환 후 CNN에 넣을지
각각의 장단점이 있는 것 같다.
1-1) 방법은 나머지 신경을 안써도 되지만 메커니즘 구현에 있어서 불편하다 rank가 하나 늘어버려서 직관적이지 않고 오류를 발생시킬 가능성도 높다.
1-2) 아직은 내 생각에 이 방법이 맞는 것 같다. 구현시에도 직관적이고 강화학습과 연계해서도 구현하기 편해질 것 같다. gym library의 atari에서도 컬러여서 그렇긴 하지만 모두 rank가 3이니 호환성을 위해서도 3으로 하는게 맞는 것 같다.
2-1) 마음은 편하겠지만, agent와 gym을 연계시킬 때 env의 space를 인수로 넣을 수도 있는데 그러면 호환성이 많이 떨어지게 된다.
내 생각은 1-2) 방법이 가장 맞는 것 같다.(2022-11-08)
4.
3번과 비슷한 문제이다. 방법론적이라거나 테크니컬한 문제는 아니고 일종의 UI/UX 문제인 것 같다. 환경을 만들 때 agent를 위해 어디까지 마중나가야 할까의 문제이다. 예를 들어 나는 어떤 게임을 구현하기 위해서는 [9, 9]의 공간만으로 충분하다고 하자. 이는 [weight, height] 라고 할때, 이것을 CNN에 적용하고 싶다면 rank를 3개로 늘려야 한다. 이는 [channel, weight, height]가 될 수도 있고 [weight, height, channel]이 될 수도 있다. 내 생각의 발전 순서를 나열해 보겠다.
- 환경만 신경쓴다. 예를 들어
[9, 9]공간에 0, 1만 필요하다면observation_space를MultiBinary([9, 9])로 정의한다. - 대부분
CNN은 3개의rank를 필요로 하고 atari같은 경우도 대부분[width, height, 3]을 반환한다. 그러므로 이용자의 편의를 위해rank를 3으로 만드는 것 정도는 해도 되지 않을까 생각했다. Wrapper에 대해서 알게 되었고 생각보다gym라이브러리에 대해서 환경에 대한 수정이 용이하다는 것을 알게 되었다. 그래서 다시 1번과 같은 생각을 하게 되었다.
무한 반복이다. 환경 그 자체로 집중해야 할 지 아니면 그 외의 것도 고려해야할지 고려한다면 어디까지 고려해야 할 지 더 많은 코드를 보고 정해야 겠다.
// TODO
5.
내가 만든 환경인 gym-woodoku를 Nature DQN1을 이용하여 수렴시키는 데 실패했다.(2022-11-14) 정말 많은 파라미터도 많이 바꿔봤다
state가 0, 1으로만 되어있어서 CNN 모델 통과시 신호가 약해지는 것 아닌가 싶어서 numpy로 된 state에 255를 곱했다.reward가 너무 커서 그런것 아닌가 싶어서(0~10정도로 형성) 0.1을 곱하여 스케일링 했다.step을 10M번 진행하고epsilon-greedy에서 입실론의 최댓값(1.0)에서 최솟값(0.1) 까지 선형적으로 감소시키는 구간을 0.1(1M)에서 0.3(3M)으로 늘려보았다.reward가 충분히 sparse할 수 있기 때문에discount factor를 0.99에서 0.999로 늘려보았다.- target network 업데이트 주기를 조절하였다
결국 실패했다. 안되는 이유를 곰곰히 생각해봤는데 다음과 같다.
조금이라도 개선이 되지 않는 것으로 보아 알고리즘 파라미터의 문제는 아닌 것 같았다. 가장 유력한 실패원인은 너무 큰 action_space 때문인 것 같다. 예를 들어 아직 optimal action을 찾지 못한 state가 있다면 optimal action을 찾기 위해 exploration을 해야 한다. 그런데 243(9*9*3)개중에 optimal action이 다른 것으로 걸려 있다면 나는 나머지 242개를 탐색해야 하는데 epsilon이 0.1이라고 하면 나머지 action 모두를 탐색하기 위해 엄청난 step이 필요할 것이다. 또한 근사되긴 하지만 observation 또한 경우의 수가 \(2^{9*9 + 3*5*5}\)이다. 각각의 observation에 243개의 action을 모두 탐색하려면 이는 엄청난 시간이 필요할 것 같다. PPO 등 Policy Based Learning으로 도전해야겠다.
6.
(2023-01-07) gym-snakegame 환경을 학습하는 데 실패하였다. 일반적인 snake game 규칙을 따른다. 알고리즘은 DQN을 사용하였다. snake가 자기몸에 박거나 벽을 박으면 -20을 보상으로 주고 target을 먹으면 20을 보상으로 줬다. 이러니 학습이 느린 것 같아서 움직일 때마다 보상을 -1을 줬다. 더 빨리 target을 먹게 하려는 의도였다. 하지만 target을 더 빨리 먹기는 커녕 벽에 빨리 박아버려서 return을 최대화하였다. 먹으러 가는 것보다 빨리 박아버려서 죽는 것이 더 낫다고 학습이 된 것 같다. 움직일때는 보상을 0으로 하여 학습하는게 맞는 듯 하다.
7.
렌더링은 미리 해두는 것이 좋다. (간단한 환경이라면) 복잡한 알고리즘보다 큰 틀 안에서 렌더링을 미리 해두고 내부 알고리즘을 구현하면 디버그하기 편한다.
8.
observation이 올바르게 출력되는 지 확인한다. 예를 들어 어떤 보드게임을 나타낸다고 할 때 uint8 형식으로 넘파이 배열이 저장되어 있다고 하자. 그럼 이 observation을 Wrapper 수준에서 어떤 수로 나눈다면 그 observation 또한 uint8이다. 이럴 때는 Wrapper에서 데이터 타입을 바꿔주던가, 해당 환경을 수정해야 한다.
9.
실험 설계에 관한 부분이다. 영상과 점수 혹은 보상의 누적은 모두 저장해놓고 대응시킬 수 있도록 저장하는 것이 좋은 것 같다.
나의 경우 처음에는 episode 200마다 영상을 저장했는데 영상은 episode 단위로 index를 저장하고 에피소드의 리턴은 따로 step 기준으로 저장하여 둘을 대응시킬 수가 없어 그냥 시간의 흐름에 따라 판별할 수 밖에 없었다. 한 에피소드가 너무 길어지면 무한루프에 빠졌는지를 판별하기 위해 STEP 별로 리턴값을 대응시켰는데 X축을 한 에피소드로 두고 한 에피소드의 길이, 한 에피소드의 return값, 그리고 에피소드별로 영상을 저장하는 것이 좋은 것 같다.
10.
STEP을 10M번을 돌렸는데 학습이 모두 안될 수도 있다. 무한루프는 학습 마무리가 안정적이지 못하기 때문에 STEP을 유한숫자로 하는 경우가 있는데 곡선이 수렴되지 않고 상승곡선인데 STEP이 끝날 수 있다. 이럴 경우를 대비하여 학습중간이나 마무리시에 신경망의 weight를 저장해두는 것이 좋다.
11.
사용시에 wrappers 간의 관계를 신경써야 한다. 예를 들어 RecordEpisodeStatistics를 사용하고 그것에 RewardWrappers를 사용하면 반영이 되지 않는다.
wrappers를 다양하게 사용할 경우 신경을 써야 한다. 기록의 경우에는 당연히 맨 마지막에 써야 한다.
이에 대한 자세한 내용은 gym Wrappers 정리에 서술하였다.
12.
MSE Loss는 사용을 자제하는 것이 좋은 것 같다. snake game을 학습시키는데 MSE Loss를 사용하였더니 Loss가 말도안되게 크게 나왔다.
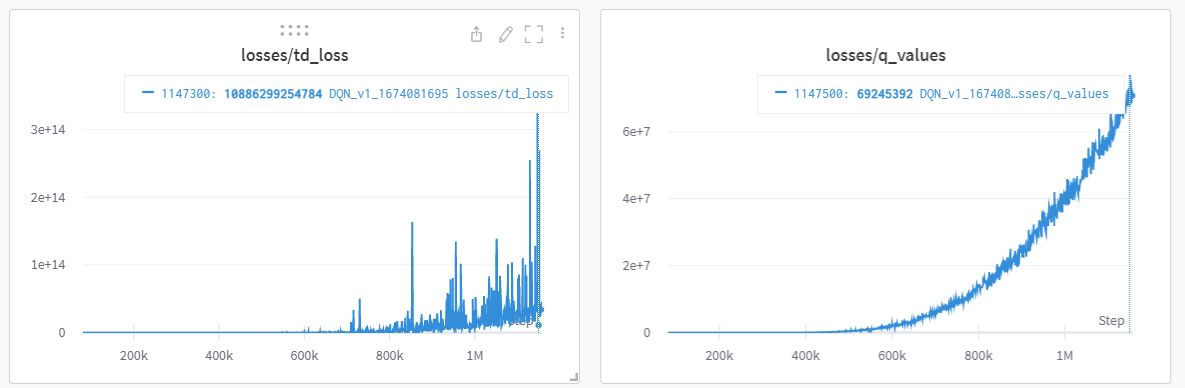
가능하면 Huber Loss를 사용해야겠다.
13.
이건 진짜 삽질이다. tqdm을 이용하여 iteration의 진행을 확인하는데 iter/s의 숫자가 점점 줄어드는 것이 확인되었다(속도가 줄어드는 것이다) 그래서 GPU 모니터링을 확인해보니 메모리 누수는 발견되지 않았고 GPU활용률도 40%에서 안정적이었다. 더군다나 SPS(Steps Per Second)수치도 떨어졌다. 그래서 다음과 같은 것들을 바꿔보았다.
- 리눅스 -> 윈도우10
- 노트북 -> 커맨드 실행
- Loss가 너무 커서 그런가 싶어서 MSE Loss -> Huber Loss
- GPU RAM이 부족한가 싶어서 Desktop -> Colab
하지만 원인은 다른 곳에 있었다. tqdm과 SPS의 속도 계산 방식이 전체 STEP을 전체 시간으로 나누는 것인데 학습 시간 전에 8만 step을 진행할때 학습을 안할때보다 학습 시간이 20~40배 정도 빠르다. 이러고 학습을 시작하면 step 중간에 학습이 들어가기 때문에 iteration속도가 뚝 떨어지는데 위의 계산은 모든 것(인지는 확실하지 않고 최근의 다수)을 합산해서 평균하기 때문에 학습이 멈출때까지 속도는 떨어질 수 밖에 없었던 것이다.
그래도 이 과정으로 인해 얻은 결론이 몇 개 있어 적는다. 환경에 따라 다를 수 있다.
- 노트북 실행보다 파이썬 파일로 커맨드 실행하는 것이 더 빠르다.
- Loss Function과 Batch의 개수는 엄청난 Loss를 부를 수 있다.
- 천만 단위 숫자를 제곱하던 일단위 숫자를 제곱하던 속도의 차이는 극히 작다 (천만 단위가 더 빠르던 경우도 있다) 이는 파이썬의 특징인 듯하다.
- train-frequency 하이퍼 파라미터에 대해서 무조건 1이 좋은 것 아닌가 생각하였는데 (Atari에서) 4도 많이 쓰이는 것 같다. 무조건 학습을 자주하는 것이 좋은것만은 아니라는 생각이 들었다.
- 어차피 리눅스 쓰긴 하지만 리눅스가 윈도우보다 빠르다.
1: Mnih, V., Kavukcuoglu, K., Silver, D. et al. Human-level control through deep reinforcement learning. Nature 518, 529–533 (2015).