파이썬 복습
1. namedtuple
1-1. 기본 설명
namedtuple 인스턴스는 일반 튜플과 마찬가지로 메모리 효율적이다. 인스턴스마다 딕셔너리를 포함하고 있지 않기 때문이다. 각 namedtuple은 namedtuple() 팩토리 함수를 사용해 생성되는 자신의 클래스로 표현할 수 있다. 새 클래스의 이름과 각 요소에 대한 문자열이 인자로 올 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
import collections
Person = collections.namedtuple('Person', 'name age')
bob = Person(name='Bob', age=30)
print('\nRepresentation:', bob)
jane = Person(name='Jane', age=29)
print('\nField by name:', jane.name)
print('\nFields by index:')
for p in [bob, jane]:
print('{} is {} years old'.format(*p))
여기서 Person을 같게 하는데 헷갈리지 않기 위해 그렇게 한다고 한다
출력
1
2
3
4
5
6
7
Representation: Person(name='Bob', age=30)
Field by name: Jane
Fields by index:
Bob is 30 years old
Jane is 29 years old
1-2. 상속에서의 활용
1
2
3
4
5
6
7
8
9
from collections import namedtuple
class Point(namedtuple('Point', 'row col')):
pass
c = Point('test1', 'test2')
print(c.row)
출력
1
test1
클래스에 상속될 경우 그 클래스의 namedtuple로 활용되는 듯 하다.
2. @property
2-1. 기본 설명
일반적으로 인스턴스나 클래스의 속성에 접근하면 저장된 값이 반환된다. 프로퍼티property는 접근되는 순간 값이 계산되는 특수한 속성이다.
장식자 @property는 바로 다음에 나오는 메서드를 보통 메서드를 호출할 때 붙여야 하는 괄호 () 없이 단순 속성인 것처럼 접근할 수 있게 한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
import math
class Circle(object):
def __init__(self, radius):
self.radius = radius
# 원의 몇가지 프로퍼티들
@property
def area(self):
return math.pi*self.radius**2
@property
def perimeter(self):
return 2*math.pi*self.radius
c = Circle(4.0)
print("c.radius : ", c.radius)
print("c.area : ", c.area)
print("c.perimeter : ", c.perimeter)
출력
c.area = 2 와 같이 속성을 재정의하려고 시도할 경우
AttributeError: can't set attribute
에러가 발생한다
2-2. 속성 설정/삭제
프로퍼티는 속성을 설정하거나 삭제하는 연산을 가로챌 수도 있다. 이를 위해서는 프로퍼티에 설정 setter 메서드나 삭제 delete 메서드를 추가하면 된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
class Foo(object):
def __init__(self, name):
self.__name = name
@property
def name(self):
return self.__name
@name.setter
def name(self, value):
if not isinstance(value, str):
raise TypeError("Must be a string!")
self.__name = value
@name.deleter
def name(self):
raise TypeError("Can't delete name")
f = Foo("Guido")
n = f.name # f.name()를 호출한다. - 얻기(get) 함수
f.name = "Monty" # 설정 함수인 name(f, "Monty") 을 호출한다.
f.name = 45 # 설정 함수인 name(f, 45)을 호출한다 -> Type Error
del f.name # 삭제 함수인 name(f)을 호출한다 -> Type Error
속성 name은 @property 장식자와 관련 메서드를 사용해서 먼저 읽기 전용 프로퍼티로 정의된다. 이어서 나오는 @name.setter와 @name.deleter 장식자는 설정 및 삭제 연산을 위한 추가 메서드를 프로퍼티에 연결시킨다.
추가 메서드는 원본 프로퍼티 메서드의 이름과 동일해야 한다. 앞의 예에서 name의 실제 값은 __name 속성에 저장된다. 이 속성의 이름을 정하는 데에는 특별한 규칙은 없지만 프로퍼티와 구별하기 위해 프로퍼티의 이름과는 달라야 한다.
3. 정적 메서드와 클래스 메서드
클래스 정의에서 모든 함수는 인스턴스에 대해서 작동하는 것으로 가정한다. 이 때문에 첫 번째 매개변수로서 항상 self가 전달된다. 이 밖에도 클래스 정의에 볼 수 있는 흔히 사용되는 두 종류의 메서드가 더 있다.
3-1. 정적 메서드 static method
정적 메서드 static method 는 클래스에 의해 정의되는 네임스페이스에 들어 있는 보통의 함수다 정적 메서드는 인스턴스에 대해서 작동하지 않는다. 정적 메서드를 정의하려면 다음과 같이 @staticmethod 장식자를 사용하면 된다.
1
2
3
4
class Foo(object):
@staticmethod
def add(x, y):
return x + y
정적 메서드를 호출하려면 그저 클래스 이름을 앞에 붙이기만 하면 된다. 추가 정보를 넘겨줄 필요는 없다. 다음 예를 보자
1
x = Foo.add(3, 4) # x = 7
정적 메서드는 다양한 방식으로 인스턴스를 생성하는 클래스를 작성할 때 흔히 사용된다. 클래스에서 __init__() 함수는 단 하나만 존재할 수 있기 때문에 다음에서 볼 수 있듯이 다른 생성 함수를 정적 메서드로서 정의하는 경우가 종종 있다
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
import time
class Date(object):
def __init__(self, year, month, day):
self.year = year
self.month = month
self.day = day
@staticmethod
def now():
t = time.localtime()
return Date(t.tm_year, t.tm_mon, t.tm_mday)
@staticmethod
def tomorrow():
t = time.localtime(time.time() + 86400)
return Date(t.tm_year, t.tm_mon, t.tm_mday)
# 날짜 객체를 몇 개 생성하는 예
a = Date(1967, 4, 9)
b = Date.now() # 정적 메서드 now()를 호출한다.
c = Date.tomorrow() # 정적 메서드 tomorrow()를 호출한다.
3-2. 클래스 메서드 class method
클래스 메서드 class method는 클래스 자체를 객체로 보고 클래스 객체에 대해 작동하는 메서드를 말한다. 클래스 메서드는 @classmethod 장식자를 사용해서 정의한다. 인스턴스 메서드와 다른 점은 첫 번째 인수로서 관례적으로 cls라는 이름을 가진 클래스가 전달된다는 점이다. 다음은 한 예이다
1
2
3
4
5
6
7
8
9
10
class Times(object):
factor = 1
@classmethod
def mul(cls, x):
return cls.factor*x
class TwoTimes(Times):
factor = 2
x = TwoTimes.mul(4) # Times.mul(TwoTimes, 4)를 호출한다. 결과는 8이다.
앞의 예에서 mul()에 클래스 TwoTimes가 객체로 전달되었다. 앞의 예가 약간 난해하게 보일 수도 있을 것 같다. 클래스 메서드는 약간 복잡해 보이지만 실용적인 용도로 쓰인다. 예를 들어, 앞에서 정의한 Date 클래스로부터 상속을 받아서 다음과 같이 약간 커스터마이징 하였다고 하자.
1
2
3
4
class EuroDate(Date):
# 유럽의 날짜 표현 방식대로 문자열 변환을 수행해주도록 수정
def __str__(self):
return "%02d/%02d/%4d" % (self.day, self.month, self.year)
이 클래스는 Date에서 상속받았기 때문에 Date의 모든 기능을 갖게 된다. 그러나 now() 와 tomorrow() 메서드는 의도한 대로 작동하지 않는다. 예를 들어, 누군가가 EuroDate.now()를 호출하면 EuroDate 객체가 아닌 Date 객체가 반환된다. 다음과 같이 클래스 메서드를 사용함으로써 이 문제를 해결할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
import time
class Date(object):
...
@classmethod
def now(cls):
t = time.localtime()
# 적절한 타입의 객체를 생성한다.
return cls(t.tm_year, t.tm_mon, t.tm_mday)
class EuroDate(Date):
...
a = Date.now() # Date.now(Date)가 호출되어서 Date 객체가 반환된다
b = EuroDate.now() # Date.now(EuroDate)가 호출되어서 EuroDate 객체가 반환된다.
정적 메서드와 클래스 메서드를 사용할 때 파이썬에서는 이 메서드들을 인스턴스 메서드와 별개의 네임스페이스로 관리하지 않는다. 이 때문에 다음과 같이 정적 메서드와 클래스 메서드를 인스턴스에 대해서 호출할 수 있다.
1
2
d = Date(1967, 4, 9)
b = d.now() # Date.now(Date)를 호출한다
이것이 가능하다는 점은 d.now()가 인스턴스 d와는 아무런 관련이 없다는 점 때문에 혼동을 가져올 수 있다. 이 부분은 파이썬의 객체 시스템이 스몰톡이나 루비같은 다른 객체지향 언어와 다른 점 중 하나이다. 다른 객체지향언어에서는 클래스 메서드와 인스턴스 메서드가 엄격하게 분리되어 있다.
이동, 비트 연산자
| 연산 | 설명 |
|---|---|
x << y |
왼쪽 이동 |
x >> y |
오른쪽 이동 |
x & y |
비트 and |
x \| y |
비트 or |
x ^ y |
비트 `xor(exclusive or) |
~x |
비트 negation |
assert 와 __debug__
assert 문으로 프로그램에 디버깅 코드를 넣을 수 있다. assert문의 일반적인 형식은 다음과 같다
1
assert test [, msg]
여기서 test는 True와 False로 평가되는 표현식이다. 만약 test가 False로 평가되면 assert문에 지정한 메시지인 msg와 함께 AssertionError에러가 발생한다. 다음은 한 예이다
1
2
3
def write_data(file, data):
assert file, "write_data: file not defined!"
...
프로그램이 올바르게 작동하기 위해서 반드시 수행되어야 하는 코드에는 assert 문을 사용하지 않도록 한다. 왜냐하면 파이썬이 최적화 모드(인터프리터에 -o 옵션)로 실행될 때 assert 문이 실행되지 않기 때문이다. 특히 사용자의 입력을 확인하는 데 assert 문을 사용하면 안 된다. assert문은 항상 참이어야 하는 것들을 검사하는 데 사용한다. 참이 아닌 것이 있으면 사용자의 오류가 아니라 프로그램의 버그 때문인 것이다.
예를 들어, 앞의 예에서 wrtie_data() 가 최종 사용자에 의해서 사용되는 함수라면 assert 문은 if문과 에러 처리 코드로 대체되어야 한다.
assert 와 더불어 파이썬에서는 읽기 전용 내장 변수인 __debug__ 가 제공된다. 이 변수는 인터프리터가 최적 모드(인터프리터에 -O 옵션)로 수행되지 않는 한 True로 설정된다. 필요에 따라 프로그램에서 이 변수를 확인할 수 있고, 이 변수가 설정된 경우 추가적인 에러 검사 과정을 수행할 수도 있다. 인터프리터에서 __debug__ 변수가 구현되는 방식은 최적화되어 있어서 추가적인 if 문의 제어 흐름 로직은 코드에 실제로 포함되지 않는다. 파이썬이 일반 모드로 실행되는 경우 if __debug__문 아래에 있는 문장들은 if문 없이 프로그램 코드에 직접 나타난다. 최적화 모드에서는 if __debug__ 문과 관련된 모든 문장들이 프로그램에서 완전히 제거된다.
assert 문과 __debug__ 를 사용하면 프로그램을 두 가지 모드를 통해 효율적으로 개발할 수 있다. 예를 들어, 디버그 모드에서는 코드가 올바르게 작동하는지를 검증하기 위한 단언 및 버그 검사 코드를 자유롭게 사용할 수 있다. 최적화 모드에서는 이러한 모든 추가적인 검사들이 자동으로 제거되기 때문에 성능에 영향이 없다.
객체 비교와 순서 매기기
1. 객체 검사 및 해싱을 위한 특수 메서드
| 메서드 | 설명 |
|---|---|
__bool__(self) |
진리값 검사를 위해 False 나 True 를 반환 |
__hash__(self) |
정수 해시 색인을 계산 |
__bool__() 메서드는 진리값 검사를 수행하는 데 사용되며 True 또는 False를 반환해야 한다. 이 메서드가 정의되지 않을 경우에는 진리값을 결정하기 위해서 __len()__ 메서드가 대신 사용된다.
1
2
3
4
5
6
7
8
9
10
class Truth:
def __init__(self, num):
self.num = num
def __bool__(self):
return self.num != 0
print(bool(Truth(0))) # False
print(bool(Truth(3))) # True
__hash__() 메서드는 사전에서 키로서 쓰일 수 있는 객체에서 정의해야 하는 메서드이다. 반환되는 값은 동일한 두 객체에 대해서 동일한 값을 갖는 정수여야 한다. 또한, 변경 가능한 객체에서는 이 메서드를 정의하면 안 된다. 객체에 변경이 가해지면 해시 값이 변경되어 이후의 사전 검색에서 객체를 찾을 수 없기 때문이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
class Obj:
def __init__(self, a, b):
self.a = a
self.b = b
def _key(self):
return (self.a, self.b)
def __eq__(self, other):
return self._key() == other._key()
def __hash__(self):
return hash(self._key())
o1 = Obj(1, 2)
o2 = Obj(3, 4)
print(hash(o1)) # -3550055125485641917
print(hash(o2)) # 1079245023883434373
d = {o1: 1, o2: 2}
2. 비교를 위한 메서드
|메서드|결과|
|-|-|
|__it__(self, other)|self < other|
|__le__(self, other)|self <= other|
|__gt__(self, other)|self > other|
|__ge__(self, other)|self >= other|
|__eq__(self, other)|self == other|
|__ne__(self, other)|self != other|
객체는 하나 이상의 관계 연산자 <, >, <=, >=, ==, != 를 구현할수 있다. 각 메서드는 두 개의 인수를 받으며, 불리언 값, 리스트, 또는 다른 아무 파이썬 타입 등 어떤 종류의 객체이든 반환할 수 있다. 예를 들어, 수치 관련 패키지의 경우 두 행렬의 원소별 비교를 수행할 때 그 결과로서 행렬을 반환할 수 있다. 비교가 수행될 수 없는 경우에는 예외가 발생되기도 한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
class Compare:
def __init__(self, n):
self.n = n
def __eq__(self, other):
return self.n == other
def __lt__(self, other):
return self.n < other
def __le__(self, other):
return self.n <= other
c = Compare(10)
print(c < 10) # False / __lt__()
print(c <= 10) # True / __le__()
print(c > 10) # Error : __gt__() is not defined
print(c == 10) # True / __eq__()
print(c != 10) # False / __ne__() or not __eq__()
isinstance(object, classobj)
object 가 classobj 또는 classobj 의 하위 클래스의 인스턴스이거나 추상 기반 클래스인 classobj 에 속할 경우 True 를 반환한다. classobj 매개변수는 타입이거나 클래스의 튜플일 수도 있다. 예를 들어, isinstance(s, (list, tuple)) s 가 튜플이거나 리스트이면 True 를 반환한다.
1
2
3
4
5
6
7
8
9
10
11
class A(object): pass
class B(A): pass
class C(object): pass
a = A()
b = B()
c = C()
print(isinstance(a, A)) # True
print(isinstance(b, A)) # True / B는 A로부터 파생
print(isinstance(b, C)) # False / B는 C로부터 파생되지 않았다.
사전의 메서드와 연산
| 항목 | 설명 |
|---|---|
len(m) |
m에 있는 항목 개수를 반환한다 |
m[k] |
키 k로 m의 항목을 반환한다. |
m[k] = x |
m[k]를 x로 설정한다. |
del m[k] |
m에서 m[k]를 제거한다 |
k in m |
키 k가 m에 있으면 True를 반환한다. |
m.clear() |
m에서 모든 항목을 제거한다 |
m.copy() |
m의 복사본을 생성한다 |
m.fromkeys(s, [,value]) |
순서열 s에서 키를 가져오고 모든 값을 value로 설정한 새로운 사전을 생성한다 |
m.get(k [,v]) |
m[k]가 있으면 m[k]를 반환하고 아니면 v를 반환한다 |
m.items() |
m의 모든 (키, 값) 쌍들로 구성되는 순서열을 반환한다. |
m.keys() |
m의 모든 키들의 순서열을 반환한다 |
m.pop(k [,default]) |
m[k]가 있으면 m[k]를 반환하고 m에서 제거한다. m[k]가 없을 경우 default가 제공되면 default를 반환하고, 아니면 KeyError 예외를 발생시킨다 |
m.popitem() |
m에서 임의의 (키, 값) 쌍을 제거하고 이를 튜플로서 반환한다. |
m.setdefault(k [,v]) |
m[k]가 있으면 m[k]를 반환한다. 없으면, v를 반환하고 m[k]를 v로 설정한다. |
m.update(b) |
b에 있는 모든 객체를 m에 추가한다. |
m.values() |
m에 있는 모든 값으로 구성되는 순서열을 반환한다. |
패키지
1.
모듈을 공통의 이름으로 묶는데 패키지를 사용한다. 패키지를 사용하면 모듈 사이에 이름 충돌 문제를 해결할 수 있다. 패키지를 만들려면 패키지 이름을 가진 디렉터리를 만들고 이 디렉터리에 __init__.py 파일을 생성하면 된다. 그런 다음 필요에 따라 소스 파일, 컴파일된 확장 기능, 하위 패키지 등을 추가하면 된다. 다음은 패키지를 구성하는 예를 보여준다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
Graphics/
__init__.py
Primitive/
__init__.py
lines.py
fill.py
text.py
...
Graph2d/
__init__.py
plot2d.py
Graph3d/
__init__.py
plot3d.py
Formats/
__init__.py
gif.py
png.py
tiff.py
jpeg.py
import 문으로 패키지로부터 모듈을 몇 가지 형태로 로드할 수 있다.
import Graphics.Primite.fill- 하위 모듈인
Graphics.Primitive.fill을 로드한다. 이 모듈의 내용에 접근하려면Graphics.Primitive.fill.floodfill(img, x, y, color)같이 이름을 직접 써주어야 한다.
- 하위 모듈인
from Graphics.Primitive import fill- 하위 모듈인
fill을 로드하며 앞쪽 패키지 이름 없이 사용할 수 있다. ex)fill.floodfill(img, x, y, color)
- 하위 모듈인
from Graphics.Primitive.fill import floodfill- 하위 모듈
fill을 로드하며floodfill함수를 바로 사용할 수 있다. ex)floodfill(img, x, y, color)
- 하위 모듈
패키지의 일부가 처음으로 로드될 때 __init__.py 파일에 있는 코드가 실행된다. 이 파일은 비어있을 수 있고 패키지를 초기화하는 코드를 담을 수도 있다. import를 실행하는 동안 만나게 되는 모든 __init__.py 파일이 차례대로 실행된다. 즉, import Graphics.Primitive.fill이 실행되면 먼저 Graphics 디렉터리에 있는 __init__.py 파일이 실행되고 다음으로 Primitive 디렉터리에 있는 __init__.py 파일이 실행 된다.
패키지와 관련해서 다음 문장을 처리할 때 약간의 문제가 있을 수 있다.
1
from Graphics.Primitive import *
보통 프로그래머는 패키지와 연관된 모든 하위 모듈을 현제 네임스페이스로 임포트하려고 이 문장을 사용한다. 그러나 시스템마다 파일 이름과 관련된 규칙이 다르기 때문에(특히 대 소문자 구별 여부) 어떤 모듈을 임포트해야 할지를 정확하게 결정하게 어렵다. 그 결과, 이 문장은 단순히 Primitive 디렉터리에 있는 __init__.py 파일 안에서 정의된 이름을 임포트한다. 이러한 작동 방식을 바꾸려면 패키지와 연관된 모듈 이름을 담는 리스트인 __all__을 정의하면 된다. 다음과 같이 패키지의 __init__.py 파일에 이 리스트를 정의하면 된다.
1
2
3
# Graphics/Primitive/__init__.py
__all__ = ["lines", "text", "fill"]
이제 사용자가
1
from Graphics.Primitive import *
문을 실행하면 나열된 모든 하위 모듈이 기대했던 대로 로드된다.
한 하위 모듈에서 동일한 패키지의 다른 하위 모듈을 임포트하려는 경우에도 문제가 발생할 수 있다. 예를 들어 Graphics.Primitive.fill 모듈에서 Graphics.Primitive.lines 모듈을 임포트하려고 한다고 하자. 이렇게 하려면 단순하게 완전히 한정된 이름(예를 들어, from Graphics.Primitive import lines) 을 사용하거나 아니면 다음과 같이 패키지에 상대적인 임포트를 사용해야 한다.
1
2
3
# fill.py
from . import lines
점 . 은 현재 모듈과 동일한 디렉터리를 가리킨다. 따라서, 이 문장은 파일 fill.py 와 동일한 디렉터리에 있는 모듈 lines를 찾는다. 패키지의 하위 모듈을 임포트하려고 import module 같은 문장을 사용하지 않도록 한다. 파이썬 3에서는 import에 절대 경로가 사용된 것으로 가정하고 module을 표준 라이브러리에서 로드하려고 시도한다. 상대적인 임포트를 사용하면 더 명확하게 의도를 표현할 수 있다. 예를 들어 Graphics.Graph2D.plot2d 에서 Graphics.Primitives.lines 모듈을 임포트하려면 다음과 같이 하면 된다.
1
2
3
# plot2d.py
from ..Primitive import lines
여기서 ..은 디렉터리 밖으로 한 수준 벗어나게 하고 Primitive는 다른 패키지 디렉터리로 들어가게 한다.
import문 중 from module import symbol 형태로만 상대적인 임포트를 지정할 수 있다. 따라서 import ..Primitive.lines 나 import .lines는 문법 오류이다. 또한 symbol은 유효한 식별자여야 한다. 따라서, from .. import Primitives.lines도 적법하지 않다. 마지막으로, 상대적인 임포트는 패키지 안에서만 사용해야 한다. 단순히 다른 디렉터리에 있는 모듈을 가리키는 데 상대적인 임포트를 사용하면 안 된다.
패키지 이름을 임포트한다고 해서 그 안에 있는 모든 하위 모듈이 임포트되는 것은 아니다. 예를 들어, 다음 코드는 제대로 작동하지 않는다.
1
2
3
import Graphics
Graphics.Primitive.fill.floodfill(img, x, y, color) # 실패
이 문제를 해결하려면 import Graphics가 Graphics 디렉터리에 있는 __init__.py 파일을 실행하기 때문에 다음과 같이 상대적인 임포트를 사용하여 모든 하위 모듈을 자동으로 로드하게 만들어야 한다.
1
2
3
# Graphics.__init__.py
from . import Primitive, Graph2d, Graph3d
1
2
3
# Graphics/Primitive/__init__.py
from . import lines, fill, text, ...
이제 import Graphics 문은 모든 하위 모듈을 임포트하고 완전히 한정된 이름을 사용해서 해당 모듈에 접근할 수 있게 되었다. 상대적인 임포트는 앞에서 설명한대로 사용해야 한다. 간단히 import module 같은 문장을 사용하면 표준라이브러리 모듈이 로드된다.
2.
패키지는 모듈을 모아 놓은 단위이다. 관련된 여러 개의 모듈을 계층적인 몇 개의 디렉터리로 분류해서 저장하고 계층화한다.
패키지의 구조
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
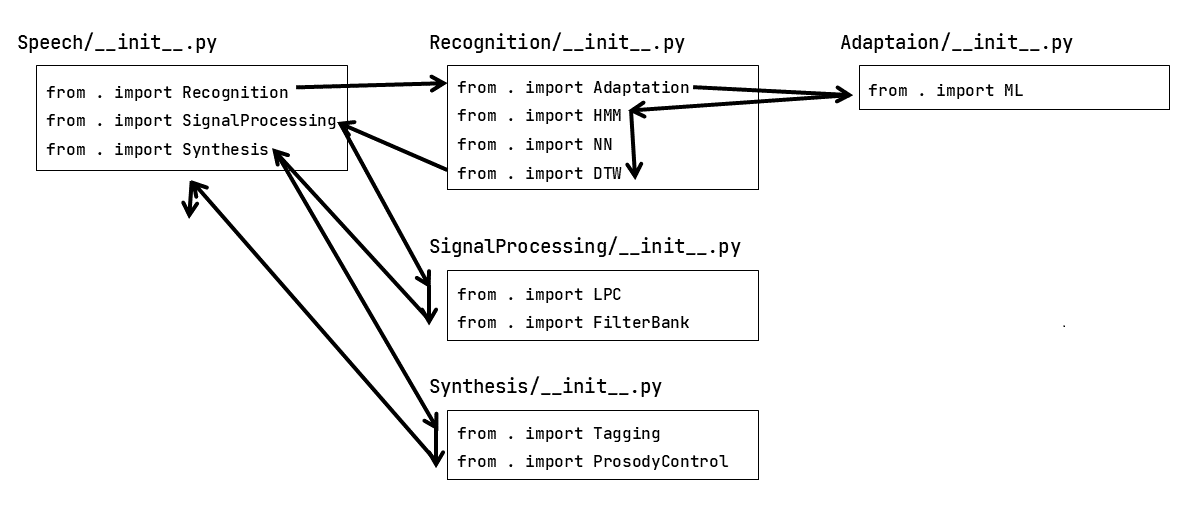
Speech/
__init__.py
SignalProcessing/
__init__.py
LPC.py
FilterBank.py
Recognition/
__init__.py
Adaptation/
__init__.py
ML.py
HMM.py
NN.py
DTW.py
Synthesis/
__init__.py
Tagging.py
ProsodyControl.py
__init__.py 파일
각 디렉터리에는 __init__.py파일이 반드시 있어야 한다. 이 파일은 패키지를 가져올 때 자동으로 실행되는 초기화 스크립트이다. 이 파일이 없으면 해당 폴더는 파이썬 패키지로 간주하지 않는다. __init__.py 파일은 패키지를 초기화하는 어떠한 파이썬 코드도 포함할 수 있다. 예를 들어 Speech/__init__.py 파일은 다음과 같다.
1
2
3
4
5
6
__all__ = ['Recognition', 'SignalProcessing', 'Synthesis']
__version__ = '1.2'
from . import Recognition # 상대 가져오기
from . import SignalProcessing
from . import Synthesis
__all__ 변수는 from Speech import * 문에 의해서 가져오기를 할 모듈이나 패키지 이름들을 지정한다.
1
2
3
4
5
from Speech import *
>>> print(dir())
['Recognition', 'SignalProcessing', 'Synthesis', '__builtins__', '__doc__', '__name__', '__package__']
__init__.py 이름 공간은 패키지 Speech 이름 공간이다. 즉, __init__.py 이름 공간에 정의하는 이름들은 패키지 Speech 이름 공간에 그대로 드러난다.
1
2
3
4
5
6
7
8
9
10
11
12
13
import Speech
>>> print(Speech.__version__)
'1.2'
>>> print(Speech.__all__)
['recognition', 'SignalProcessing', 'Synthesis']
>>> print(dir(Speech))
['Recognition', 'SignalProcessing', 'Synthesis', '__all__', '__builtints__', '__cached__', '__doc__', '__file__', '__name__', '__package__', '__path__', '__version__']
>>> Speech.Recognition
<module 'Speech.Recognition' from '~~~\Speech\Recognition\__init__.py'>
from . import Recognition과 같은 문에 의해서 하위 패키지인 Recognitiion이 가져와 진다. 이 경우 역시 Recognition/__init__.py 파일이 실행되어 패키지를 초기화한다. Recognition/__init__.py 파일의 예는 다음과 같다.
1
2
3
4
5
6
__all__ = ['Adaptation', 'HMM', 'NN', 'DTW']
from . import Adaptation
from . import HMM
from . import NN
from . import DTW
import Speech 문에 의해서 실행되는 코드의 순서는 다음과 같다.
미래 기능 활성화
예전 버전의 파이썬과 호환성 문제가 있을 수 있는 새로운 언어 기능은 파이썬의 새로운 릴리스에서 보통 비활성화되어 있다. 이 기능을 활성화하려면
1
from __future__ import feature
문을 사용하면 된다. 다음 예를 보자
1
2
3
# 새로운 나누기 작동 방식을 활성화 한다
from __future__ import division
이 문장은 모듈이나 프로그램에서 가장 앞에 나와야 한다. 또한 __future__ import의 유효 범위는 이 문장이 사용된 모듈에 국한된다. 따라서 미래 기능을 임포트한다고 하더라도 파이썬 라이브러리 모듈의 작동 방식이 변경되지 않으며, 인터프리터의 예전 작동 방식에 의존하는 오래된 코드의 작동방식도 변경되지 않는다
| 기능 이름 | 설명 |
|---|---|
print_function |
print문 대신 파이썬 3.0의 print() 함수를 사용한다. 파이썬 2.6에서 처음 도입되었고 파이썬 3.0에서 기본으로 활성화된다. |
__future__ 에서는 어떤 기능 이름도 제거된 적이 없다. 따라서 나중 파이썬 버전에서 어떤 기능이 기본으로 활성화된다 하더라도, 이 기능을 사용하는 기존 코드는 문제가 발생하지 않는다.
platform.system()
시스템/OS 이름을 반환합니다, 가령 'Linux', 'Darwin', 'Java', 'Windows' 값을 판별할 수 없으면 빈 문자열이 반환됩니다.
subprocess
subprocess 모듈은 새로운 프로세스 생성, 입출력 스트림 제어, 반환 코드 처리 작업을 일반화한 함수와 객체들을 제공한다. 이 모듈은 os, popen2, commands 같은 다양한 다른 모듈에 있는 기능을 한 곳에 모아놓았다
1
Popen(args, **params)
새 명령을 하위 프로세스로 실행하고 새 프로세스를 나타내는 Popen 객체를 반환한다. args 에 있는 명령은 'ls -l' 같은 문자열 또는 ['ls', '-l'] 같은 문자열 리스트로 지정한다. parms는 하위 프로세스의 다양한 속성을 제어하기 위해 설정하는 키워드 인수들을 나타낸다. 다음 키워드 인수들을 인식한다
| 키워드 | 설명 |
|---|---|
shell |
True이면 os.system() 함수처럼 작동하는 유닉스 셸을 사용하여 명령을 실행한다.(명령어를 문자열로 쉘에 전달하려면 True로 설정해야 한다.) 기본 셸은 /bin/sh이지만 executable 설정을 통해 변경할 수 있다. shell의 기본 값은 None이다. |
1
p.communicate([input])
input로 주어진 데이터를 자식 프로세스의 표준 입력으로 전달하여 자식 프로세스와 통신한다. 일단 데이터를 전달하고 나면 표준 출력과 표준 에러에서 결과를 수집하면서 프로세스가 종료되기를 기다린다. 문자열인 stdout, stderr를 담은 튜플 (stdout, stderr)를 반환한다. 자식 프로세스로 보내는 데이터가 없으면 input을 None으로 설정한다(기본 값)
warnings
1
2
import warnings
warnings.filterwarnings('ignore')
warnings.filterwarnings(action, message='', category=Warning, module='', lineno=0, append=False)
경고 필터 명세 목록에 항목을 삽입한다. append 가 참이면 끝에 삽입, 인자의 형을 확인하고 message와 module 정규식을 컴파일 한 후 경고 필터 목록에 튜플로 삽입, 목록 앞쪽의 항목이 우선한다. 생략된 인자의 기본값은 모든 것과 일치하는 것이다.
예시 해석
warnings.filterwarnings의 인자로
|값|처리|
|-|-|
|ignore|일치하는 경고를 인쇄하지 않습니다|
를 삽입한다. 다른 인자는 default를 따르므로 경고 필터 명세에 ignore을 맨 앞에 삽입하고 그것은 모든 것과 일치하는 것이므로 “모든 경고를 인쇄하지 않는다” 로 해석하면 될 것이다.
divmod(a, b)
return (a // b, a % b)
python format
1
f'{h:0>2.0f}'
f'{[variant]:[Padding number][align][전체 자리수].[소수점 이하 자리수][type]}'
예시 해석
h라는 변수(float)를 오른쪽 정렬하여 빈 곳은 0으로 채우고 전체 2자리로 맞추고 소수점 이하는 0자리수만 출력한다.
urllib.request
urljoin
1
urllib.parse.urljoin(base, url, allow_fragments=True)
base와 url을 결합시켜 전체 absolute URL을 만든다. 비공식적으로 base의 구성 요소, 특히 addressing scheme, 네트워크위치 및 경로(의 일부)를 사용하여 상대적 URL에 누락된 구성 요소를 제공한다.
1
2
3
>>> from urllib.parse import urljoin
>>> urljoin('http://www.cwi.nl/%7Eguido/Python.html', 'FAQ.html')
'http://www.cwi.nl/%7Eguido/FAQ.html'
urlretrieve
1
urllib.request.urlretrieve(url, filename=None, reporthook=None, data=None)
URL로 표시된 네트워크 객체를 로컬 파일에 복사한다.
Path
Path.exists
1
Path.exists()
path가 기존의(현재 존재하는) 경로를 가리키고 있으면 True반환
Path.mkdir
1
Path.mkdir(mode=511, parents=False, exist_ok=False)
주어진 경로에 대해 새로운 경로를 생성한다.
Path, opeartor /
/ 연산을 오버로딩하여 탐색한 결과를 Path 클래스로 리턴한다.
1
2
3
4
>>> p = Path('/etc')
>>> q = p / 'init.d' / 'reboot'
>>> q
PosixPath('/etc/init.d/reboot')
PurePath.stem
path의 마지막 요소를 suffix를 제거하고 반환한다.
1
2
3
4
5
6
>>> PurePosixPath('my/library.tar.gz').stem
'library.tar'
>>> PurePosixPath('my/library.tar').stem
'library'
>>> PurePosixPath('my/library').stem
'library'
with as
with 문을 이용하면 다음과 같이 더 편하게 작업할 수 있다. with 문 안에 있는 동안 객체 f를 이용하여 파일에 관련된 작업을 할 수 있고, with 문에서 빠져나오면서 자동으로 닫히기까지 한다.
1
2
with open('t1.txt', 'w') as f:
f.write('위대한 세종대왕')
gzip
gzip 모듈은 GNU gzip 프로그램과 호환되는 파일을 읽거나 쓰는 데 사용할 수 있는 GzipFile 클래스를 제공한다. GzipFile 객체는 파일이 자동으로 압축되고 압축해제된다는 점을 제외하고는 보통의 파일처럼 작동한다
GzipFile
1
gzip.GzipFile(filename=None, mode=None, compresslevel=9, fileobj=None, mtime=None)
GzipFile을 연다. filename은 파일 이름이고, mode는 r, rb, a, ab, w, wb 중 하나이다, compresslevel은 1에서 9사이의 정수 값을 가지며 압축 레벨을 제어한다. 1은 가장 빠르지만 낮은 압축률을 제공하고 9(기본 값)는 가장 느리지만 높은 압축률을 제공한다. fileobj는 기존 파일 객체를 나타낸다. 주어질 경우 filename이라는 이름을 가지는 파일 대신에 주어진 객체를 사용한다.
open
1
gzip.open(filename, mode='rb', compresslevel=9, encoding=None, errors=None, newline=None)
GzipFile(filename, mode, compresslevel)과 동일하다. 기본 모드는 rb이며 기본 compresslevel은 9이다.
바이너리나 텍스트 모드로 gzip으로 압축된 파일을 열고, 파일 객체를 반환합니다.
shutil
shutil 모듈은 복사, 삭제, 이름 변경 등 고수준 파일 연산을 수행하는 데 사용한다. 이 모듈에 있는 함수들은 실제 파일과 디렉터리에 대해서만 작동한다. 이름 있는 파이프(named pipe), 블록 장치(block device) 같은 파일 시스템에서 특수한 종류의 파일에 대해서는 사용할 수 없다. 또한 이 함수들은 파일의 고급 메타데이터(예를 들어, 자원 포크(resource fork), 생성자 코드(creator code) 등)를 올바르게 처리하지 못할 때도 있다.
copyfileobj
1
shutil.copyfileobj(f1, f2[, length])
열린 파일 객체 f1의 모든 데이터를 파일 객체 f2로 복사한다. length는 사용할 가장 큰 버퍼 크기를 명시한다. 음수 값은 데이터 전체를 한 번의 연산으로 복사하려고 시도한다.(즉, 모든 데이터를 하나의 덩어리로 읽은 다음 쓴다.)
OS
walk
1
os.walk(top, topdown=True, onerror=None, followlinks=False)
os 모듈의 walk() 함수는 디렉터리의 하위 트리 구조를 재귀적으로 검색해 가면서 디렉터리 목록과 파일 목록을 전달해 준다.
인수 top에서 시작하여 하위 디렉터리를 검색해 가면서 디렉터리 목록과 파일을 반복적으로 전달한다. 반환 형식은 튜플 (dirpath, dirnames, filenames) 이다. 디렉터리를 검색하는 순서는 인수 topdown이 결정한다. 인수 onerror는 OSError 에러가 발생하면 호출되는 함수이고, 인수 followlinks가 True이면 심볼릭 링크 파일로 지정된 디렉터리도 검색한다.
1
2
3
4
5
6
>>> import os
>>> for curdir, dirs, files in os.walk('.'):
print('curdir=', curdir)
print('dirs=', dirs[:5])
print('files=', files[:5])
print('-'*60)
1
2
3
curdir = .
dirs = ['DLLs', 'Doc', 'include', 'Lib', 'libs']
files = ['books.db', 'LICENSE.txt', 'NEWS.txt', 'pets.db', 'python.exe']
참고
데이비드 M. 비즐리, 『파이썬 완벽 가이드』, 송인철, 송현제 옮김, 인사이트(2012)
더그 헬먼, 『예제로 배우는 파이썬 표준 라이브러리』, 권석기, 김우현 옮김, 에이콘(2020)
이강성, 『파이썬3 바이블』, 프리렉(2013)
https://docs.python.org/